
We're excited to announce Background Jobs our effortless solution for queueing and managing background jobs and scheduled tasks in any .NET 8 App, implemented in true ServiceStack fashion where it seamlessly integrates into existing Apps and call existing APIs and sports a built-in Management UI to provide real-time monitoring, inspection and management of background jobs.
Background Jobs
Background Jobs
Durable Background Jobs and Scheduled Tasks for .NET 8 Apps
Durable and Infrastructure-Free
Prior to Background Jobs we've been using Background MQ for executing our background tasks which lets you queue any Request DTO to execute its API in a background worker. It's been our preferred choice as it didn't require any infrastructure dependencies since its concurrent queues are maintained in memory, this also meant they were non-durable that didn't survive across App restarts. Whilst ServiceStack MQ enables an additional endpoint for your APIs our main use-case for using it was for executing background tasks which would be better suited by purpose-specific software designed for the task.
SQLite Persistence
It uses SQLite as the backing store for its durability since it's low latency, fast disk persistence and embeddable file-based database makes it ideally suited for the task which allows creation of naturally partition-able and archivable monthly databases on-the-fly without any maintenance overhead or infrastructure dependencies making it easy to add to any .NET App without impacting or adding increased load to their existing configured databases.
Queue APIs or Commands
For even greater reuse you're able to queue your existing ServiceStack APIs as a Background Job in addition to Commands added in the last v8.3 release for encapsulating units of logic into internal invokable, inspectable and auto-retryable building blocks.
Real Time Admin UI
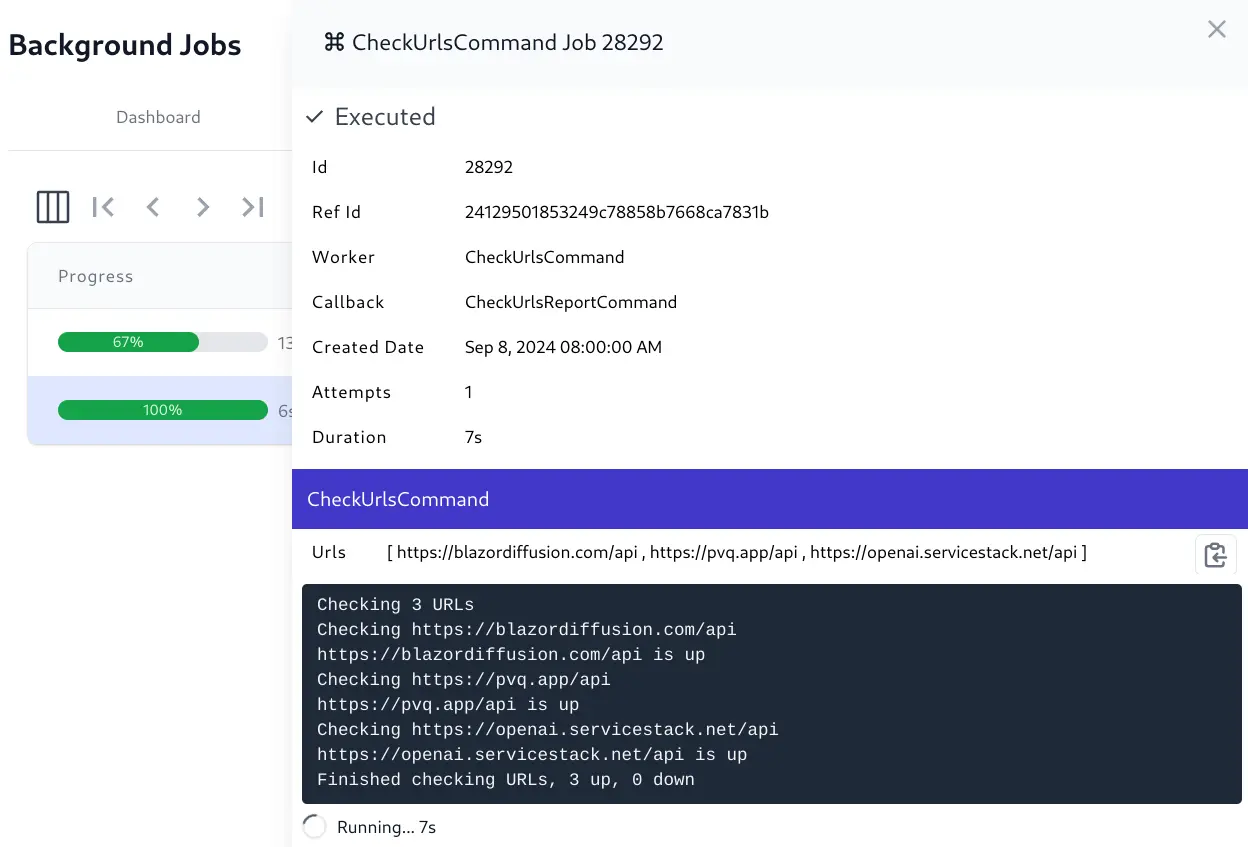
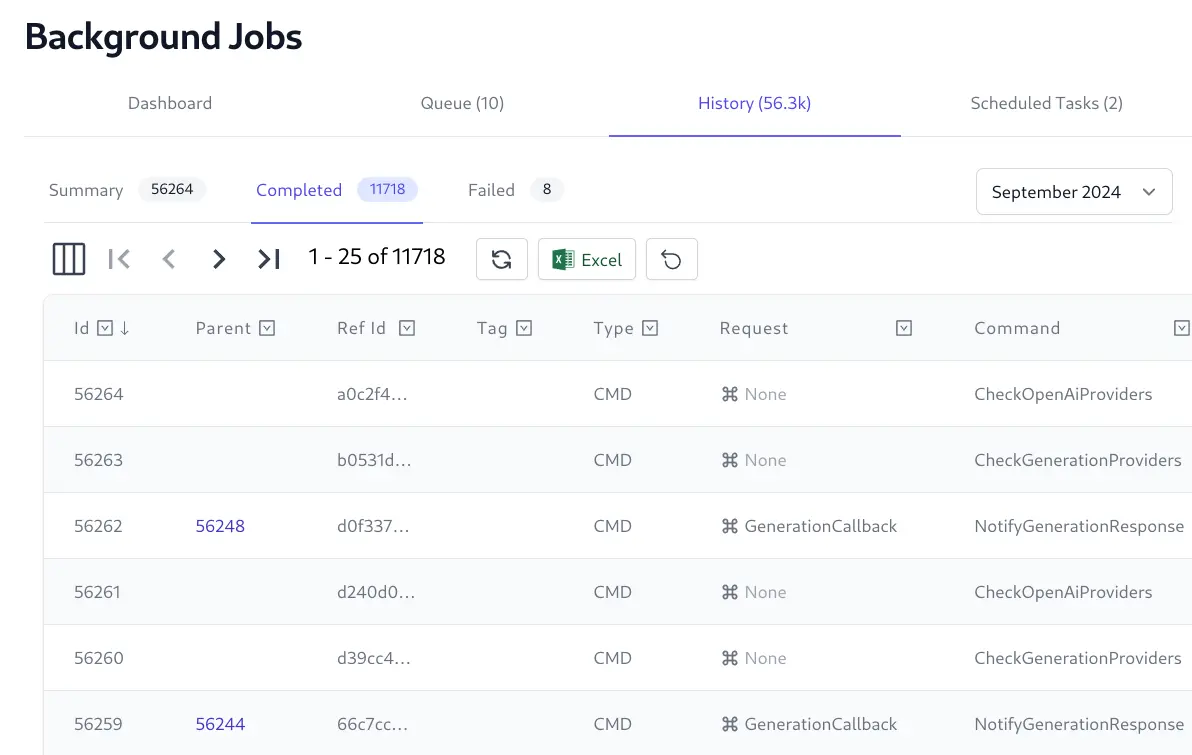
The Background Jobs Admin UI provides a real time view into the status of all background jobs including their progress, completion times, Executed, Failed and Cancelled Jobs, etc. which is useful for monitoring and debugging purposes.
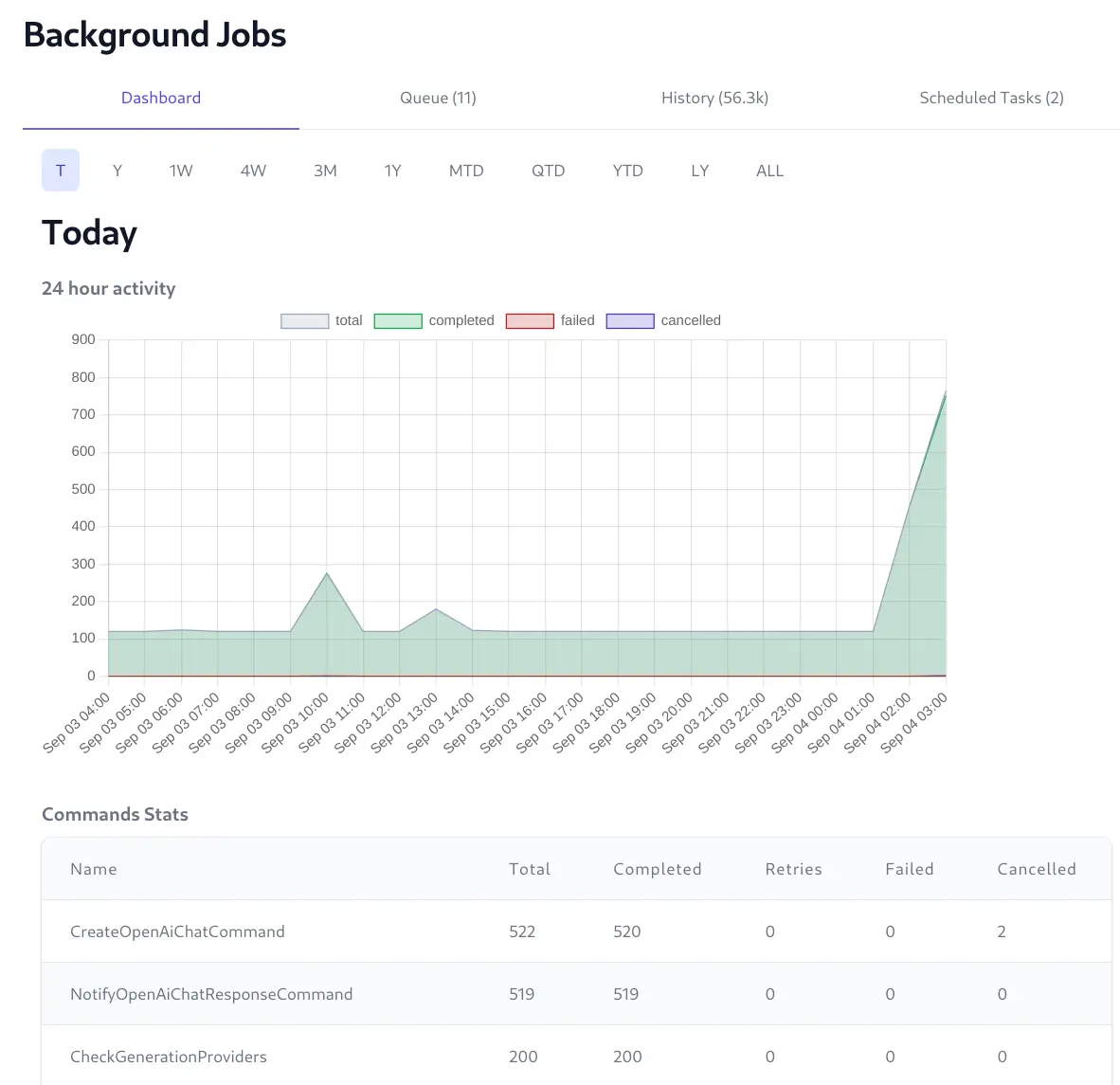
View Real-time progress of queued Jobs
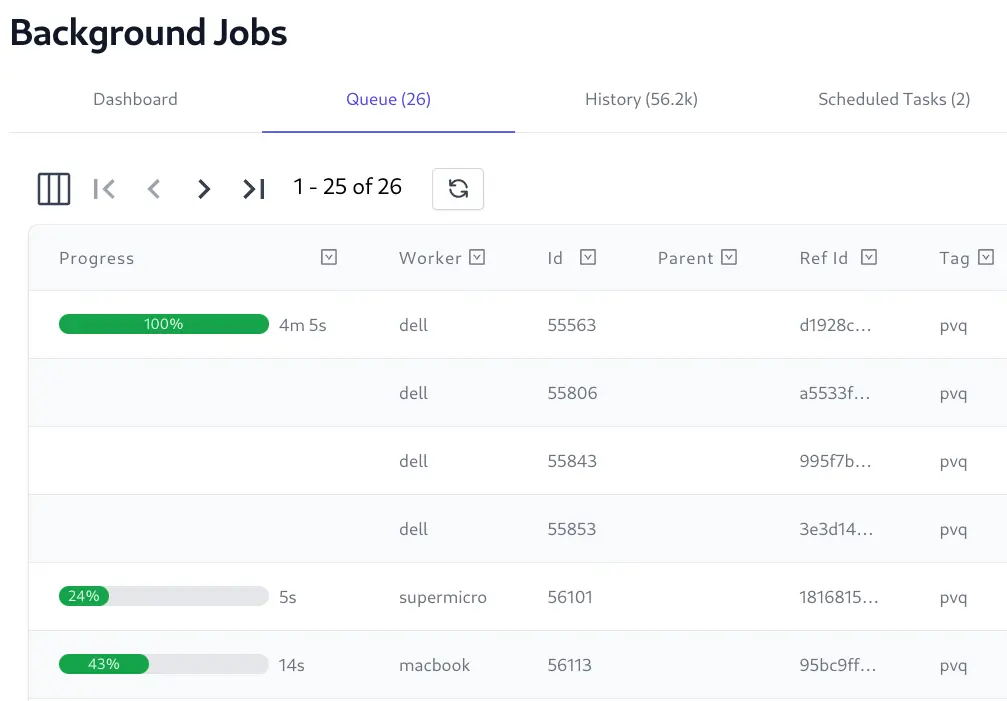
View real-time progress logs of executing Jobs
View Job Summary and Monthly Databases of Completed and Failed Jobs
View full state and execution history of each Job
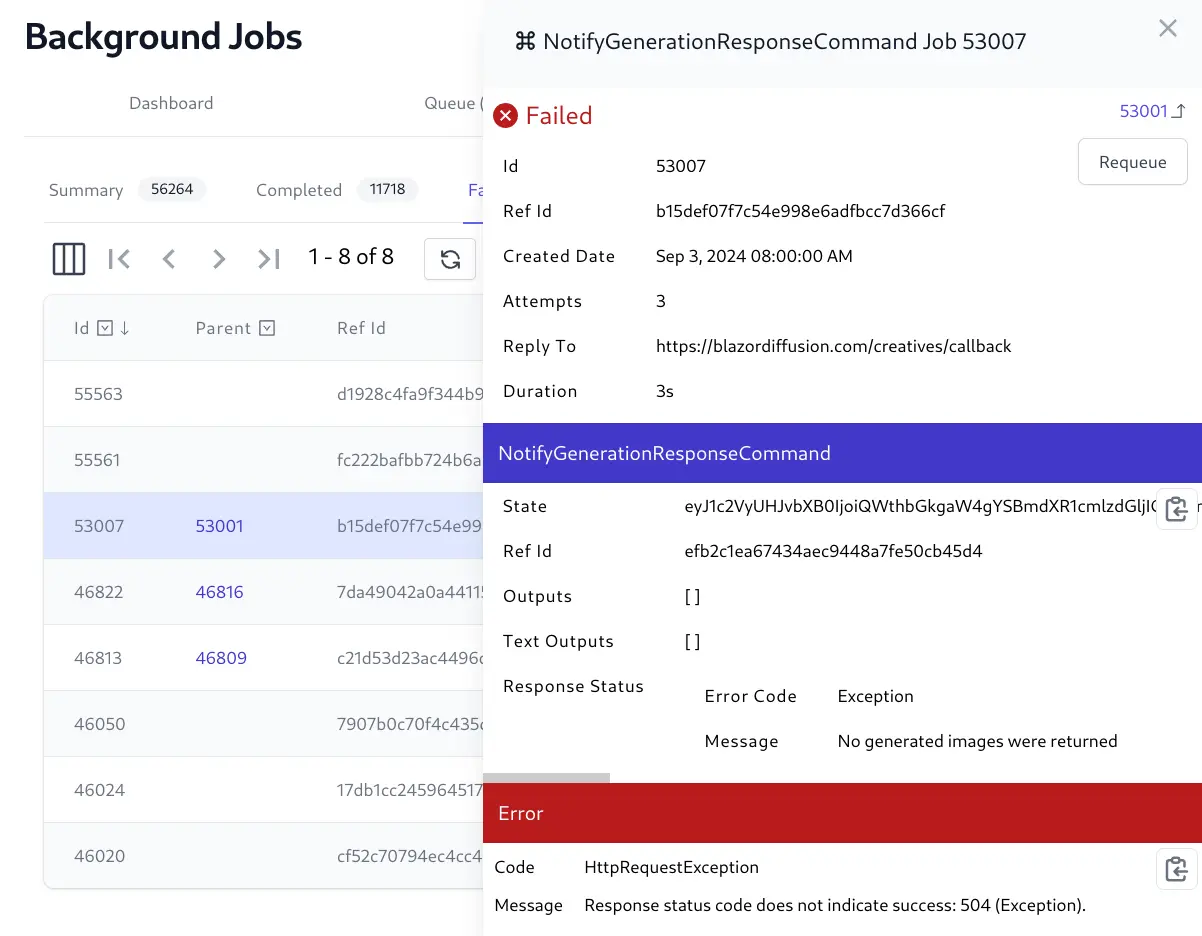
Cancel Running jobs and Requeue failed jobs
Feature Overview
Even in its v1 release it packs all the features we wanted in a Background Jobs solution:
- No infrastructure dependencies
- Monthly archivable rolling Databases with full Job Execution History
- Execute existing APIs or versatile Commands
- Commands auto registered in IOC
- Scheduled Reoccurring Tasks
- Track Last Job Run
- Serially execute jobs with the same named Worker
- Queue Jobs dependent on successful completion of parent Job
- Queue Jobs to be executed after a specified Date
- Execute Jobs within the context of an Authenticated User
- Auto retry failed jobs on a default or per-job limit
- Timeout Jobs on a default or per-job limit
- Cancellable Jobs
- Requeue Failed Jobs
- Execute custom callbacks on successful execution of Job
- Maintain Status, Logs and Progress of Executing Jobs
- Execute transitive (i.e. non-durable) jobs using named workers
- Attach optional
Tag,BatchId,CreatedBy,ReplyToandArgswith Jobs
Please let us know of any other missing features you'd love to see implemented.
Install
As it's more versatile and better suited, we've replaced the usage of Background MQ with ServiceStack.Jobs in all .NET 8 Identity Auth Templates for sending Identity Auth Confirmation Emails when SMTP is enabled. So the easiest way to get started with ServiceStack.Jobs is to create a new Identity Auth Project, e.g:
x new blazor-vue MyApp
Exiting .NET 8 Templates
Existing .NET 8 Projects can configure their app to use ServiceStack.Jobs by mixing in:
x mix jobs
Which adds the Configure.BackgroundJobs.cs Modular Startup
configuration and a ServiceStack.Jobs NuGet package reference to your project.
Usage
Any API, Controller or Minimal API can execute jobs with the IBackgroundJobs dependency, e.g.
here's how you can run a background job to send a new email when an API is called in
any new Identity Auth template:
class MyService(IBackgroundJobs jobs) : Service
{
public object Any(MyOrder request)
{
var jobRef = jobs.EnqueueCommand<SendEmailCommand>(new SendEmail {
To = "my@email.com",
Subject = $"Received New Order {request.Id}",
BodyText = $"""
Order Details:
{request.OrderDetails.DumptTable()}
""",
});
//...
}
}
Which records and immediately executes a worker to execute the SendEmailCommand with the specified
SendEmail Request argument. It also returns a reference to a Job which can be used later to query
and track execution of a job.
Alternatively a SendEmail API could be executed with just the Request DTO:
var jobRef = jobs.EnqueueApi(new SendEmail {
To = "my@email.com",
Subject = $"Received New Order {request.Id}",
BodyText = $"""
Order Details:
{request.OrderDetails.DumptTable()}
""",
});
Although Sending Emails is typically not an API you want to make externally available and would want to either Restrict access or limit usage to specified users.
In both cases the SendEmail Request is persisted into the Jobs SQLite database for durability
that gets updated as it progresses through the queue.
For execution the API or command is resolved from the IOC before being invoked with the Request. APIs are executed via the MQ Request Pipeline and commands executed using the Commands Feature where it will be also visible in the Commands Admin UI.
Background Job Options
The behavior for each Enqueue* method for executing background jobs can be customized with
the following options:
Worker- Serially process job using a named worker threadCallback- Invoke another command with the result of a successful jobDependsOn- Execute jobs after successful completion of a dependent job- If parent job fails all dependent jobs are cancelled
UserId- Execute within an Authenticated User ContextRunAfter- Queue jobs that are only run after a specified dateRetryLimit- Override default retry limit for how many attempts should be made to execute a jobTimeoutSecs- Override default timeout for how long a job should run before being cancelledRefId- Allow clients to specify a unique Id (e.g Guid) to track jobTag- Group related jobs under a user specified tagCreatedBy- Optional field for capturing the owner of a jobBatchId- Group multiple jobs with the same IdReplyTo- Optional field for capturing where to send notification for completion of a JobArgs- Optional String Dictionary of Arguments that can be attached to a Job
Schedule Recurring Tasks
In addition to queueing jobs to run in the background, it also supports scheduling recurring tasks to execute APIs or Commands at fixed intervals.
APIs and Commands can be scheduled to run at either a TimeSpan or
CRON Expression interval, e.g:
CRON Expression Examples
// Every Minute Expression
jobs.RecurringCommand<CheckUrlsCommand>(Schedule.Cron("* * * * *"));
// Every Minute Constant
jobs.RecurringCommand<CheckUrlsCommand>(Schedule.EveryMinute, new CheckUrls {
Urls = urls
});
CRON Format
You can use any unix-cron format expression supported by the HangfireIO/Cronos library:
|------------------------------- Minute (0-59)
| |------------------------- Hour (0-23)
| | |------------------- Day of the month (1-31)
| | | |------------- Month (1-12; or JAN to DEC)
| | | | |------- Day of the week (0-6; or SUN to SAT; or 7 for Sunday)
| | | | |
| | | | |
* * * * *
The allowed formats for each field include:
| Field | Format of valid values |
|---|---|
| Minute | 0-59 |
| Hour | 0-23 |
| Day of the month | 1-31 |
| Month | 1-12 (or JAN to DEC) |
| Day of the week | 0-6 (or SUN to SAT; or 7 for Sunday) |
Matching all values
To match all values for a field, use the asterisk: *, e.g here are two examples in which the minute field is left unrestricted:
* 0 1 1 1- the job runs every minute of the midnight hour on January 1st and Mondays.* * * * *- the job runs every minute (of every hour, of every day of the month, of every month, every day of the week, because each of these fields is unrestricted too).
Matching a range
To match a range of values, specify your start and stop values, separated by a hyphen (-). Do not include spaces in the range. Ranges are inclusive. The first value must be less than the second.
The following equivalent examples run at midnight on Mondays, Tuesdays, Wednesdays, Thursdays, and Fridays (for all months):
0 0 * * 1-50 0 * * MON-FRI
Matching a list
Lists can contain any valid value for the field, including ranges. Specify your values, separated by a comma (,). Do not include spaces in the list, e.g:
0 0,12 * * *- the job runs at midnight and noon.0-5,30-35 * * * *- the job runs in each of the first five minutes of every half hour (at the top of the hour and at half past the hour).
TimeSpan Interval Examples
jobs.RecurringCommand<CheckUrlsCommand>(Schedule.Interval(TimeSpan.FromMinutes(1)));
// With Example
jobs.RecurringApi(Schedule.Interval(TimeSpan.FromMinutes(1)), new CheckUrls {
Urls = urls
});
That can be registered with an optional Task Name and Background Options, e.g:
jobs.RecurringCommand<CheckUrlsCommand>("Check URLs", Schedule.EveryMinute,
new() {
RunCommand = true // don't persist job
});
INFO
If no name is provided, the Command's Name or APIs Request DTO will be used
Idempotent Registration
Scheduled Tasks are idempotent where the same registration with the same name will either create or update the scheduled task registration without losing track of the last time the Recurring Task, as such it's recommended to always define your App's Scheduled Tasks on Startup:
public class ConfigureBackgroundJobs : IHostingStartup
{
public void Configure(IWebHostBuilder builder) => builder
.ConfigureServices((context,services) => {
services.AddPlugin(new CommandsFeature());
services.AddPlugin(new BackgroundsJobFeature());
services.AddHostedService<JobsHostedService>();
}).ConfigureAppHost(afterAppHostInit: appHost => {
var services = appHost.GetApplicationServices();
var jobs = services.GetRequiredService<IBackgroundJobs>();
// App's Scheduled Tasks Registrations:
jobs.RecurringCommand<MyCommand>(Schedule.Hourly);
});
}
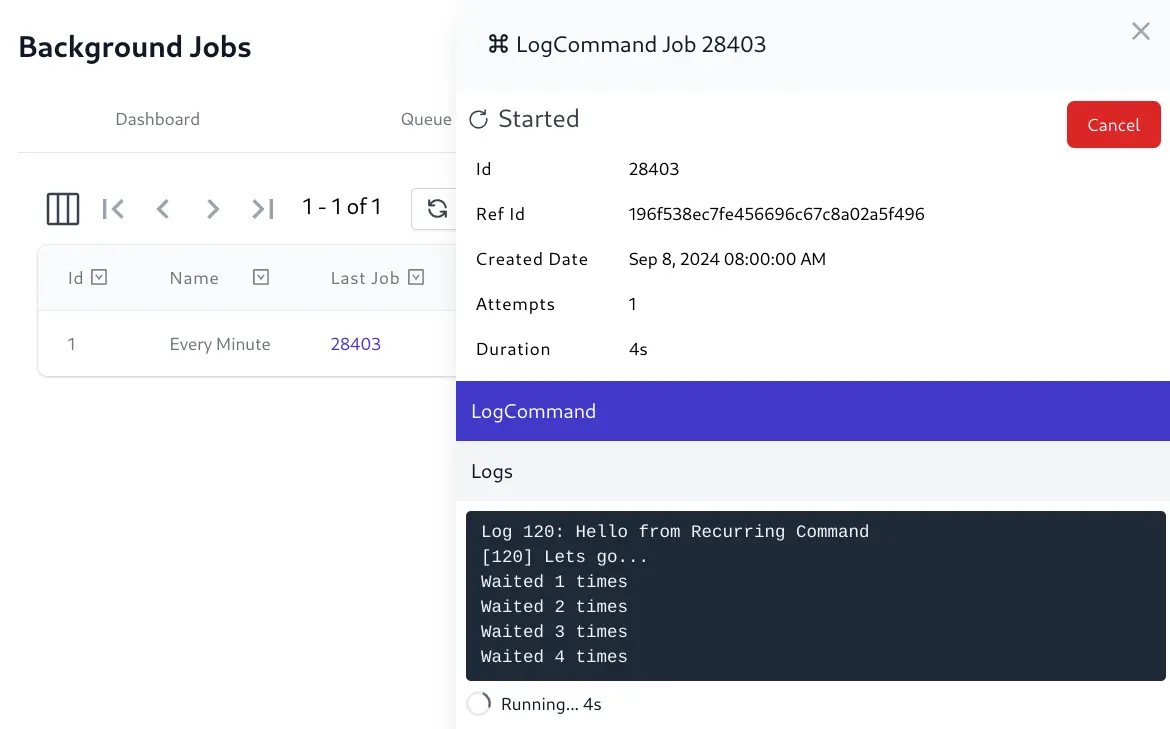
Background Jobs Admin UI
The last job the Recurring Task ran is also viewable in the Jobs Admin UI:
Executing non-durable jobs
IBackgroundJobs also supports RunCommand methods to be able to execute jobs transiently
(i.e. non-durable), which is useful for commands that want to be serially executed by a named worker
but don't need to be persisted.
You could use this to queue system emails to be sent by the same smtp worker and are happy to avoid tracking its state and execution history in the Jobs database.
var job = jobs.RunCommand<SendEmailCommand>(new SendEmail { ... },
new() {
Worker = "smtp"
});
In this case RunCommand returns the actual BackgroundJob instance that will be updated by
the worker.
You can also use RunCommandAsync if you prefer to wait until the job has been executed. Instead
of a Job it returns the Result of the command if it returned one.
var result = await jobs.RunCommandAsync<SendEmailCommand>(new SendEmail {...},
new() {
Worker = "smtp"
});
Serially Execute Jobs with named Workers
By default jobs are executed immediately in a new Task, we can also change the behavior to instead execute jobs one-by-one in a serial queue by specifying them to use the same named worker as seen in the example above.
Alternatively you can annotate the command with the [Worker] attribute if you always want
all jobs executing the command to use the same worker:
[Worker("smtp")]
public class SendEmailCommand(IBackgroundJobs jobs) : SyncCommand<SendEmail>
{
//...
}
Use Callbacks to process the results of Commands
Callbacks can be used to extend the lifetime of a job to include processing a callback to process its results. This is useful where you would like to reuse the the same command but handle the results differently, e.g. the same command can email results or invoke a webhook by using a callback:
jobs.EnqueueCommand<CheckUrlsCommand>(new CheckUrls { Urls = allUrls },
new() {
Callback = nameof(EmailUrlResultsCommand),
});
jobs.EnqueueCommand<CheckUrlsCommand>(new CheckUrls { Urls = criticalUrls },
new() {
Callback = nameof(WebhookUrlResultsCommand),
ReplyTo = callbackUrl
});
Callbacks that fail are auto-retried the same number of times as their jobs, which if they all fail then the entire job is also marked as failed.
Run Job dependent on successful completion of parent
Jobs can be queued to only run after the successful completion of another job, this is useful for when you need to kick off multiple jobs after a long running task has finished like generating monthly reports after monthly data has been aggregated, e.g:
var jobRef = jobs.EnqueueCommand<AggregateMonthlyDataCommand>(new Aggregate {
Month = DateTime.UtcNow
});
jobs.EnqueueCommand<GenerateSalesReportCommand>(new () {
DependsOn = jobRef.Id,
});
jobs.EnqueueCommand<GenerateExpenseReportCommand>(new () {
DependsOn = jobRef.Id,
});
Inside your command you can get a reference to your current job with Request.GetBackgroundJob()
which will have its ParentId populated with the parent job Id and job.ParentJob containing
a reference to the completed Parent Job where you can access its Request, Results and other job
information:
public class GenerateSalesReportCommand(ILogger<MyCommandNoArgs> log)
: SyncCommand
{
protected override void Run()
{
var job = Request.GetBackgroundJob();
var parentJob = job.ParentJob;
}
}
Atomic Batching Behavior
We can also use DependsOn to implement atomic batching behavior where from inside our
executing command we can queue new jobs that are dependent on the successful execution
of the current job, e.g:
public class CheckUrlsCommand(IHttpClientFactory factory, IBackgroundJobs jobs)
: AsyncCommand<CheckUrls>
{
protected override async Task RunAsync(CheckUrls req, CancellationToken ct)
{
var job = Request.GetBackgroundJob();
var batchId = Guid.NewGuid().ToString("N");
using var client = factory.CreateClient();
foreach (var url in req.Urls)
{
var msg = new HttpRequestMessage(HttpMethod.Get, url);
var response = await client.SendAsync(msg, ct);
response.EnsureSuccessStatusCode();
jobs.EnqueueCommand<SendEmailCommand>(new SendEmail {
To = "my@email.com",
Subject = $"{new Uri(url).Host} status",
BodyText = $"{url} is up",
}, new() {
DependsOn = job.Id,
BatchId = batchId,
});
}
}
}
Where any dependent jobs are only executed if the job was successfully completed. If instead an exception was thrown during execution, the job will be failed and all its dependent jobs cancelled and removed from the queue.
Executing jobs with an Authenticated User Context
If you have existing logic dependent on a Authenticated ClaimsPrincipal or ServiceStack
IAuthSession you can have your APIs and Commands also be executed with that user context
by specifying the UserId the job should be executed as:
var openAiRequest = new CreateOpenAiChat {
Request = new() {
Model = "gpt-4",
Messages = [
new() {
Content = request.Question
}
]
},
};
// Example executing API Job with User Context
jobs.EnqueueApi(openAiRequest,
new() {
UserId = Request.GetClaimsPrincipal().GetUserId(),
CreatedBy = Request.GetClaimsPrincipal().GetUserName(),
});
// Example executing Command Job with User Context
jobs.EnqueueCommand<CreateOpenAiChatCommand>(openAiRequest,
new() {
UserId = Request.GetClaimsPrincipal().GetUserId(),
CreatedBy = Request.GetClaimsPrincipal().GetUserName(),
});
Inside your API or Command you access the populated User ClaimsPrincipal or
ServiceStack IAuthSession using the same APIs that you'd use inside your ServiceStack APIs, e.g:
public class CreateOpenAiChatCommand(IBackgroundJobs jobs)
: AsyncCommand<CreateOpenAiChat>
{
protected override async Task RunAsync(
CreateOpenAiChat request, CancellationToken token)
{
var user = Request.GetClaimsPrincipal();
var session = Request.GetSession();
//...
}
}
Queue Job to run after a specified date
Using RunAfter lets you queue jobs that are only executed after a specified DateTime,
useful for executing resource intensive tasks at low traffic times, e.g:
var jobRef = jobs.EnqueueCommand<AggregateMonthlyDataCommand>(new Aggregate {
Month = DateTime.UtcNow
},
new() {
RunAfter = DateTime.UtcNow.Date.AddDays(1)
});
Attach Metadata to Jobs
All above Background Job Options have an effect on when and how Jobs are executed. There are also a number of properties that can be attached to a Job that can be useful in background job processing despite not having any effect on how jobs are executed.
These properties can be accessed by commands or APIs executing the Job and are visible and can be filtered in the Jobs Admin UI to help find and analyze executed jobs.
var jobRef = jobs.EnqueueCommand<CreateOpenAiChatCommand>(openAiRequest,
new() {
// Group related jobs under a common tag
Tag = "ai",
// A User-specified or system generated unique Id to track the job
RefId = request.RefId,
// Capture who created the job
CreatedBy = Request.GetClaimsPrincipal().GetUserName(),
// Link jobs together that are sent together in a batch
BatchId = batchId,
// Capture where to notify the completion of the job to
ReplyTo = "https:example.org/callback",
// Additional properties about the job that aren't in the Request
Args = new() {
["Additional"] = "Metadata"
}
});
Querying a Job
A job can be queried by either it's auto-incrementing Id Primary Key or by a unique RefId
that can be user-specified.
var jobResult = jobs.GetJob(jobRef.Id);
var jobResult = jobs.GetJobByRefId(jobRef.RefId);
At a minimum a JobResult will contain the Summary Information about a Job as well as the
full information about a job depending on where it's located:
class JobResult
{
// Summary Metadata about a Job in the JobSummary Table
JobSummary Summary
// Job that's still in the BackgroundJob Queue
BackgroundJob? Queued
// Full Job information in Monthly DB CompletedJob Table
CompletedJob? Completed
// Full Job information in Monthly DB FailedJob Table
FailedJob? Failed
// Helper to access full Job Information
BackgroundJobBase? Job => Queued ?? Completed ?? Failed
}
Job Execution Limits
Default Retry and Timeout Limits can be configured on the Backgrounds Job plugin:
services.AddPlugin(new BackgroundsJobFeature
{
DefaultRetryLimit = 2,
DefaultTimeout = TimeSpan.FromMinutes(10),
});
These limits are also overridable on a per-job basis, e.g:
var jobRef = jobs.EnqueueCommand<AggregateMonthlyDataCommand>(new Aggregate {
Month = DateTime.UtcNow
},
new() {
RetryLimit = 3,
Timeout = TimeSpan.FromMinutes(30),
});
Logging, Cancellation an Status Updates
We'll use the command for checking multiple URLs to demonstrate some recommended patterns and how to enlist different job processing features.
public class CheckUrlsCommand(
ILogger<CheckUrlsCommand> logger,
IBackgroundJobs jobs,
IHttpClientFactory clientFactory) : AsyncCommand<CheckUrls>
{
protected override async Task RunAsync(CheckUrls req, CancellationToken ct)
{
// 1. Create Logger that Logs and maintains logging in Jobs DB
var log = Request.CreateJobLogger(jobs,logger);
// 2. Get Current Executing Job
var job = Request.GetBackgroundJob();
var result = new CheckUrlsResult {
Statuses = new()
};
using var client = clientFactory.CreateClient();
for (var i = 0; i < req.Urls.Count; i++)
{
// 3. Stop processing Job if it's been cancelled
ct.ThrowIfCancellationRequested();
var url = req.Urls[i];
try
{
var msg = new HttpRequestMessage(HttpMethod.Get,url);
var response = await client.SendAsync(msg, ct);
result.Statuses[url] = response.IsSuccessStatusCode;
log.LogInformation("{Url} is {Status}",
url, response.IsSuccessStatusCode ? "up" : "down");
// 4. Optional: Maintain explicit progress and status updates
log.UpdateStatus(i/(double)req.Urls.Count,$"Checked {i} URLs");
}
catch (Exception e)
{
log.LogError(e, "Error checking {Url}", url);
result.Statuses[url] = false;
}
}
// 5. Send Results to WebHook Callback if specified
if (job.ReplyTo != null)
{
jobs.EnqueueCommand<NotifyCheckUrlsCommand>(result,
new() {
ParentId = job.Id,
ReplyTo = job.ReplyTo,
});
}
}
}
We'll cover some of the notable parts useful when executing Jobs:
1. Job Logger
We can use a Job logger to enable database logging that can be monitored in real-time in the
Admin Jobs UI. Creating it with both BackgroundJobs and ILogger will return a combined
logger that both Logs to standard output and to the Jobs database:
var log = Request.CreateJobLogger(jobs,logger);
Or just use Request.CreateJobLogger(jobs) to only save logs to the database.
2. Resolve Executing Job
If needed the currently executing job can be accessed with:
var job = Request.GetBackgroundJob();
Where you'll be able to access all the metadata the jobs were created with including ReplyTo
and Args.
3. Check if Job has been cancelled
To be able to cancel a long running job you'll need to periodically check if a Cancellation
has been requested and throw a TaskCanceledException if it has to short-circuit the command
which can be done with:
ct.ThrowIfCancellationRequested();
You'll typically want to call this at the start of any loops to prevent it from doing any more work.
4. Optionally record progress and status updates
By default Background Jobs looks at the last API or Command run and worker used to estimate the duration and progress for how long a running job will take.
If preferred your command can explicitly set a more precise progress and optional status update that should be used instead, e.g:
log.UpdateStatus(progress:i/(double)req.Urls.Count, $"Checked {i} URLs");
Although generally the estimated duration and live logs provide a good indication for the progress of a job.
5. Notify completion of Job
Calling a Web Hook is a good way to notify externally initiated job requests of the completion of a job. You could invoke the callback within the command itself but there are a few benefits to initiating another job to handle the callback:
- Frees up the named worker immediately to process the next task
- Callbacks are durable, auto-retried and their success recorded like any job
- If a callback fails the entire command doesn't need to be re-run again
We can queue a callback with the result by passing through the ReplyTo and link it to the
existing job with:
if (job.ReplyTo != null)
{
jobs.EnqueueCommand<NotifyCheckUrlsCommand>(result,
new() {
ParentId = job.Id,
ReplyTo = job.ReplyTo,
});
}
Which we can implement by calling the SendJsonCallbackAsync extension method with the
Callback URL and the Result DTO it should be called with:
public class NotifyCheckUrlsCommand(IHttpClientFactory clientFactory)
: AsyncCommand<CheckUrlsResult>
{
protected override async Task RunAsync(
CheckUrlsResult request, CancellationToken token)
{
await clientFactory.SendJsonCallbackAsync(
Request.GetBackgroundJob().ReplyTo, request, token);
}
}
Callback URLs
ReplyTo can be any URL which by default will have the result POST'ed back to the URL with a JSON
Content-Type. Typically URLs will contain a reference Id so external clients can correlate a callback
with the internal process that initiated the job. If the callback API is publicly available you'll
want to use an internal Id that can't be guessed (like a Guid) so the callback can't be spoofed, e.g:
$"https://api.example.com/callback?refId={RefId}"
If needed the callback URL can be customized on how the HTTP Request callback is sent.
If the URL contains a space, the text before the space is treated as the HTTP method:
"PUT https://api.example.com/callback"
If the auth part contains a colon : it's treated as Basic Auth:
"username:password@https://api.example.com/callback"
If name starts with http. sends a HTTP Header
"http.X-API-Key:myApiKey@https://api.example.com/callback"
Otherwise it's sent as a Bearer Token:
"myToken123@https://api.example.com/callback"
Bearer Token or HTTP Headers starting with $ is substituted with Environment Variable if exists:
"$API_TOKEN@https://api.example.com/callback"
When needed headers, passwords and tokens can be URL encoded if they contain any delimiter characters.
Implementing Commands
At a minimum a command need only implement the simple IAsyncCommand interface:
public interface IAsyncCommand<in T>
{
Task ExecuteAsync(T request);
}
Which is the singular interface that can execute any command.
However commands executed via Background Jobs have additional context your commands may need to
access during execution, including the BackgroundJob itself, the CancellationToken and
an Authenticated User Context.
To reduce the effort in creating commands with a IRequest context we've added a number ergonomic
base classes to better capture the different call-styles a unit of logic can have including
Sync or Async execution, whether they require Input Arguments or have Result Outputs.
Choosing the appropriate Abstract base class benefits from IDE tooling in generating the method signature that needs to be implemented whilst Async commands with Cancellation Tokens in its method signature highlights any missing async methods that are called without the token.
Sync Commands
SyncCommand- Requires No ArgumentsSyncCommand<TRequest>- Requires TRequest ArgumentSyncCommandWithResult<TResult>- Requires No Args and returns ResultSyncCommandWithResult<TReq,TResult>- Requires Arg and returns Result
public record MyArgs(int Id);
public record MyResult(string Message);
public class MyCommandNoArgs(ILogger<MyCommandNoArgs> log) : SyncCommand
{
protected override void Run()
{
log.LogInformation("Called with No Args");
}
}
public class MyCommandArgs(ILogger<MyCommandNoArgs> log) : SyncCommand<MyArgs>
{
protected override void Run(MyArgs request)
{
log.LogInformation("Called with {Id}", request.Id);
}
}
public class MyCommandWithResult(ILogger<MyCommandNoArgs> log)
: SyncCommandWithResult<MyResult>
{
protected override MyResult Run()
{
log.LogInformation("Called with No Args and returns Result");
return new MyResult("Hello World");
}
}
public class MyCommandWithArgsAndResult(ILogger<MyCommandNoArgs> log)
: SyncCommandWithResult<MyArgs,MyResult>
{
protected override MyResult Run(MyArgs request)
{
log.LogInformation("Called with {Id} and returns Result", request.Id);
return new MyResult("Hello World");
}
}
Async Commands
AsyncCommand- Requires No ArgumentsAsyncCommand<TRequest>- Requires TRequest ArgumentAsyncCommandWithResult<TResult>- Requires No Args and returns ResultAsyncCommandWithResult<TReq,TResult>- Requires Arg and returns Result
public class MyAsyncCommandNoArgs(ILogger<MyCommandNoArgs> log) : AsyncCommand
{
protected override async Task RunAsync(CancellationToken token)
{
log.LogInformation("Async called with No Args");
}
}
public class MyAsyncCommandArgs(ILogger<MyCommandNoArgs> log)
: AsyncCommand<MyArgs>
{
protected override async Task RunAsync(MyArgs request, CancellationToken t)
{
log.LogInformation("Async called with {Id}", request.Id);
}
}
public class MyAsyncCommandWithResult(ILogger<MyCommandNoArgs> log)
: AsyncCommandWithResult<MyResult>
{
protected override async Task<MyResult> RunAsync(CancellationToken token)
{
log.LogInformation("Async called with No Args and returns Result");
return new MyResult("Hello World");
}
}
public class MyAsyncCommandWithArgsAndResult(ILogger<MyCommandNoArgs> log)
: AsyncCommandWithResult<MyArgs,MyResult>
{
protected override async Task<MyResult> RunAsync(
MyArgs request, CancellationToken token)
{
log.LogInformation("Called with {Id} and returns Result", request.Id);
return new MyResult("Hello World");
}
}
SQLite Request Logs
Up until this release all of ServiceStack's database features like AutoQuery have been database agnostic courtesy of OrmLite's support for popular RDBMS's so that they integrate into an App's existing configured database.
Background Jobs is our first foray into a SQLite-only backend, as it's the only RDBMS that enables us to provide encapsulated black-box functionality without requiring any infrastructure dependencies. It's low latency, high-performance and ability to create lightweight databases on the fly make it ideal for self-managing isolated appliance backends like Background Jobs and Request Logging which don't benefit from integrating with your existing RDBMS.
The new ServiceStack.Jobs NuGet package allows us
to deliver plug and play SQLite backed features into .NET 8 Apps that are configured with any RDBMS
or without one. The next feature added is a SQLite backed provider for Request Logs
with the new SqliteRequestLogger which can be added to existing .NET 8 Apps with the
mix tool:
x mix sqlitelogs
Which adds a reference to ServiceStack.Jobs and the Modular Startup config below:
using ServiceStack.Jobs;
using ServiceStack.Web;
[assembly: HostingStartup(typeof(MyApp.ConfigureRequestLogs))]
namespace MyApp;
public class ConfigureRequestLogs : IHostingStartup
{
public void Configure(IWebHostBuilder builder) => builder
.ConfigureServices((context, services) => {
services.AddPlugin(new RequestLogsFeature {
RequestLogger = new SqliteRequestLogger(),
EnableResponseTracking = true,
EnableRequestBodyTracking = true,
EnableErrorTracking = true
});
services.AddHostedService<RequestLogsHostedService>();
});
}
public class RequestLogsHostedService(ILogger<RequestLogsHostedService> log, IRequestLogger requestLogger) : BackgroundService
{
protected override async Task ExecuteAsync(CancellationToken stoppingToken)
{
var dbRequestLogger = (SqliteRequestLogger)requestLogger;
using var timer = new PeriodicTimer(TimeSpan.FromSeconds(3));
while (!stoppingToken.IsCancellationRequested && await timer.WaitForNextTickAsync(stoppingToken))
{
dbRequestLogger.Tick(log);
}
}
}
This will use a Hosted Background Service to flush Request Logs to the requests SQLite database every 3 seconds (configurable in the PeriodicTimer).
If your App is already using RequestLogsFeature configured (e.g. with Profiling) you'll want to
remove it:
public class ConfigureProfiling : IHostingStartup
{
public void Configure(IWebHostBuilder builder) => builder
.ConfigureServices((context, services) => {
// services.AddPlugin(new RequestLogsFeature());
services.AddPlugin(new ProfilingFeature
{
IncludeStackTrace = true,
});
});
}
Rolling SQLite Databases
The benefit of using SQLite is that databases can be created on-the-fly where Requests will be persisted into isolated requests Monthly databases which can be easily archived into managed file storage instead of a singular growing database, visible in the Database Admin UI:
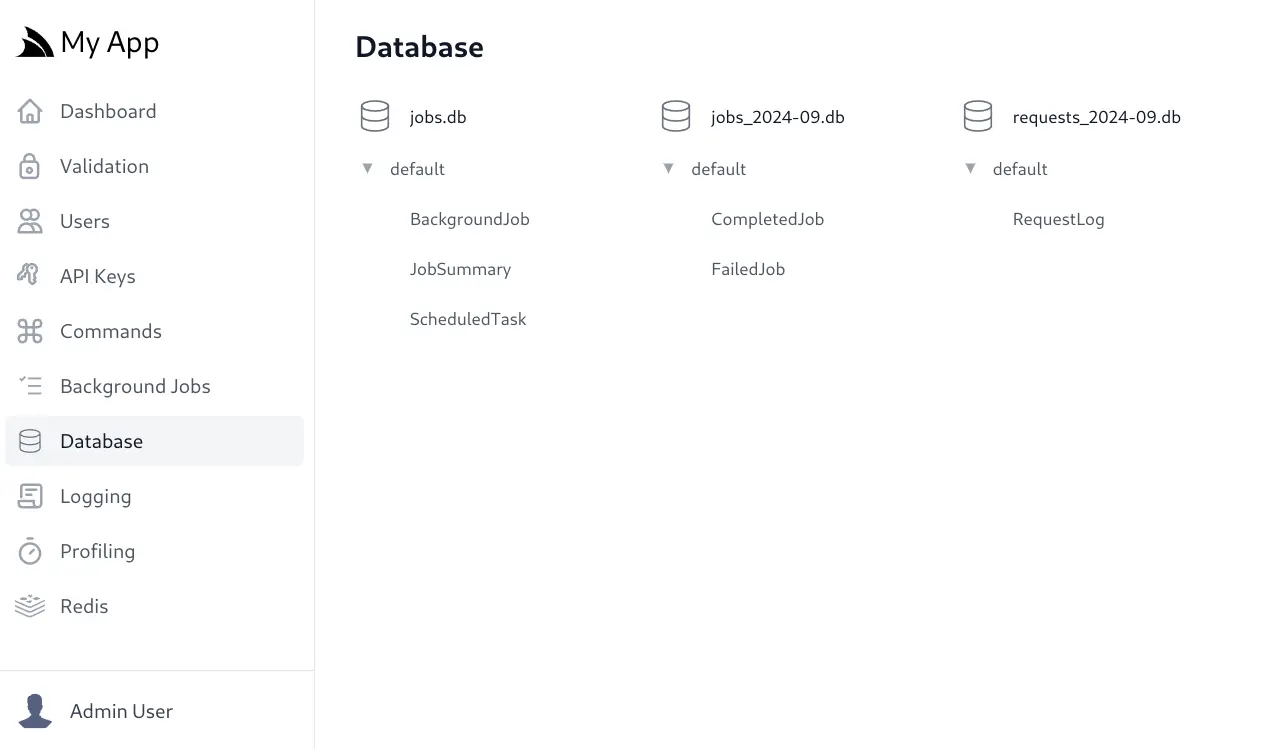
SQLite logs will also make it easier to generate monthly aggregate reports to provide key insights into the usage of your App.
AutoQuery Grid Admin Logging UI
As SQLite Requests Logs also makes it efficiently possible to sort and filter through logs, the
Logging UI will switch to using a fully queryable AutoQueryGrid when using SqliteRequestLogger:
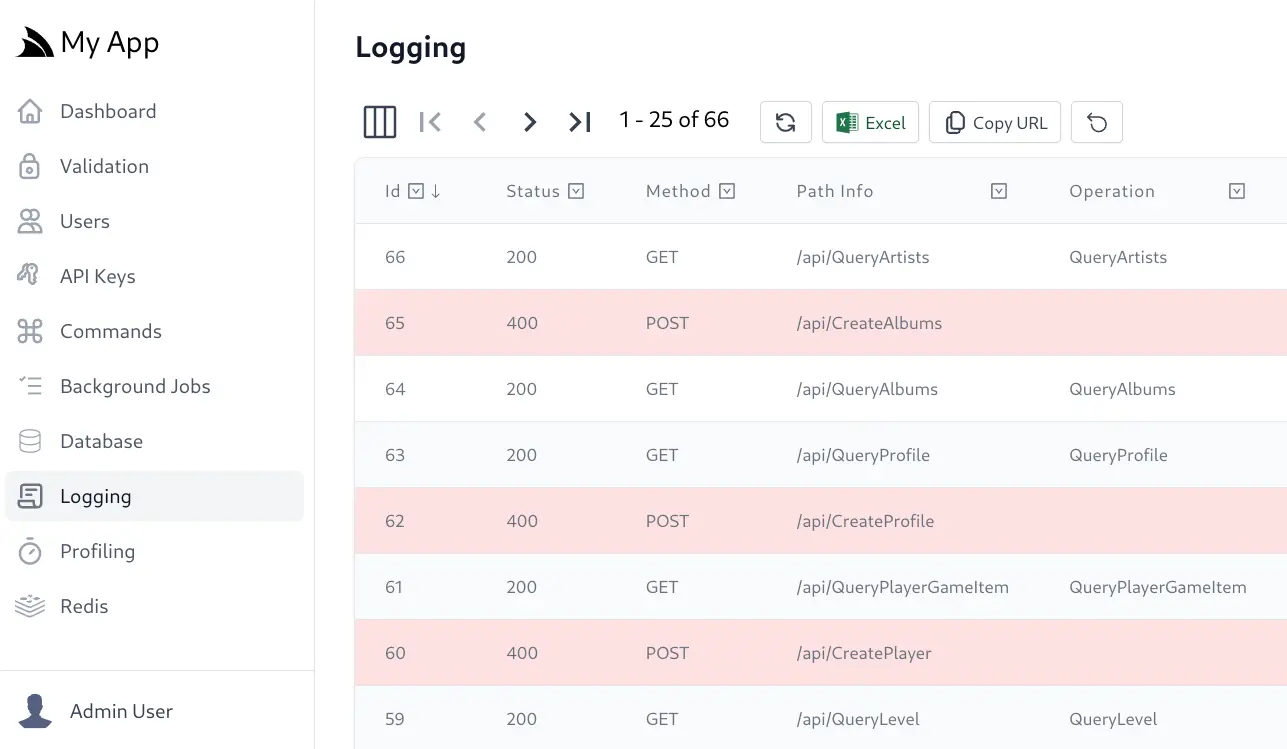
API Keys protected managed File Uploads
The Managed Files Uploads feature can now be secured
by Identity Auth API Key by setting requireApiKey:, e.g:
var fileFs = new FileSystemVirtualFiles(context.HostingEnvironment.ContentRootPath);
services.AddPlugin(new FilesUploadFeature(
new UploadLocation("pub",
fileFs,
readAccessRole: RoleNames.AllowAnon,
requireApiKey: new(),
maxFileBytes: 10 * 1024 * 1024,
resolvePath:ctx => "pub".CombineWith(ctx.Request.GetApiKey().Key, ctx.FileName)),
new UploadLocation("secure",
fileFs,
requireApiKey: new("manager"),
maxFileBytes: 10 * 1024 * 1024,
resolvePath:ctx => "secure".CombineWith(ctx.Request.GetApiKey().Key, ctx.FileName))
));
This configuration shows a pub upload location allowing for anonymous reads but all writes requiring an API Key.
The secure upload location requires an API key with a manager Scope which is required for both read and write access.
In both cases the upload locations will store the files in a sub-directory named after API Key used to upload it.
HTTP Client Factory HTTP Utils
ServiceStack now registers a named IHttpClientFactory that's configured with the same defaults as the built-in HttpUtils including using Default Credentials and support for
Brotli, Deflate and GZip compression.
You can access this via IHttpClientFactory.HttpUtilsClient() extension method, e.g:
public class MyServices(IHttpClientFactory clientFactory) : Service
{
public async Task<object> Any(MyRequest request)
{
using HttpClient client = clientFactory.HttpUtilsClient();
//...
}
}
Scalable SQLite
Ever since adding support for Litestream in our project's templates GitHub Action Deployments we've been using SQLite as the backend for our new .NET Apps as it's the most cost-effective option that frees us from needing to use a cloud managed database which lets us make use of Hetzner's much cheaper US Cloud VMs.
We're also seeing increased usage of SQLite Server Apps with Bluesky Social having moved to SQLite and all of 37 Signals new Once Web Apps using SQLite and Cloud Providers building distributed databases on top of SQLite like Cloudflare D1 and Fly.io's multi-region distributed LiteFS solution.
SQLite is a highly-performant DB that can handle a large number of concurrent read operations and 35% Faster filesystem performance for write operations with next to no latency that's often faster than other RDBMS's courtesy of its proximity to the running application which gives it unique advantages over traditional client/server RDBMS's where it's not susceptible to the N+1 Queries problem and is also able to execute your custom C# Logic inside SQL Queries using Application SQL Functions.
With litestream.io taking care of real-time replication to managed storage we just need to workaround SQLite's single concurrent writer to unlock the value, performance and unique features of SQLite in our Apps which we cover in this release with integrated support for Database Locks and Sync Commands.
Single Concurrent Writer
The primary limitation of SQLite is that it only supports a single concurrent writer, which means if you have multiple requests writing to the same database at the same time, they will need to coordinate access.
As long as we can overcome this limitation SQLite can be an excellent choice to power many Web Apps. In the previous ServiceStack v8.3 release we worked around this limitation by using MQ Command DTOs to route all DB Writes to be executed by a single Background MQ Thread.
This works great for messaging-based architectures where you can queue commands to be processed serially, but the overhead of using commands for all DB writes can be cumbersome when needing to perform sporadic writes within complex logic.
Multiple SQLite Databases
Firstly a great way to reduce contention is to use separate SQLite databases for different subsystems of your Application that way load is distributed across multiple DBs and writes across each SQLite database can be executed concurrently.
This is especially important for write heavy operations like
SQLite Request Logging or if your App stores every interaction
of your App for A/B testing, storing them in separate analytics.db databases will remove
any contention from your primary database.
The other techniques below demonstrates concurrent safe techniques for accessing an SQLite DB:
Always use Synchronous APIs for SQLite
Generally it's recommended to use non-blocking Async APIs for any I/O Operations however as SQLite doesn't make Network I/O requests and its native implementation is blocking, its Async DB APIs are just pseudo-async wrappers around SQLite's blocking APIs which just adds unnecessary overhead. For this reason we recommend always using synchronous APIs for SQLite, especially as it's not possible to await inside a lock:
lock (Locks.AppDb)
{
//Can't await inside a lock
//await Db.UpdateAsync(row);
Db.Update(row);
}
It's also safe to assume SQLite will always block since all Asynchronous I/O efforts were abandoned in favor of WAL mode which mitigates the cost of blocking fsync().
Database Locks
The new Locks class maintains an object lock for each registered database connection that can be
used to synchronize write access for different SQLite databases, e.g:
var row = db.SingleById<Table>(request.Id);
row.PopulateWithNonDefaultValues(request);
lock (Locks.AppDb)
{
Db.Update(row);
}
Locks.AppDb can be used synchronize db writes for the App's primary database, e.g. App_Data/app.db.
Whilst Locks.GetDbLock(namedConnection) can be used to get the DB Write Lock for any other
registered SQLite Database by using
the same named connection the SQLite Database Connection was registered against, e.g:
var dbFactory = new OrmLiteConnectionFactory(connStr, SqliteDialect.Provider);
dbFactory.RegisterConnection(Databases.Search,
$"DataSource=App_Data/search.db;Cache=Shared", SqliteDialect.Provider);
dbFactory.RegisterConnection(Databases.Analytics,
$"DataSource=App_Data/analytics.db;Cache=Shared", SqliteDialect.Provider);
//...
using var dbSearch = dbFactory.Open(Database.Search);
lock (Locks.GetDbLock(Database.Search))
{
dbSearch.Insert(row);
}
using var dbAnalytics = dbFactory.Open(Database.Analytics);
lock (Locks.GetDbLock(Database.Analytics))
{
dbAnalytics.Insert(row);
}
Queuing DB Writes with SyncCommand
Locks are a great option for synchronizing DB Writes that need to be executed within
complex logic blocks, however locks can cause contention in highly concurrent Apps.
One way to remove contention is to serially execute DB Writes instead which we can
do by executing DB Writes within SyncCommand* commands and using a named [Worker(Workers.AppDb)]
attribute for Writes to the primary database, e.g:
[Worker(Workers.AppDb)]
public class DeleteCreativeCommand(IDbConnection db)
: SyncCommand<DeleteCreative>
{
protected override void Run(DeleteCreative request)
{
var artifactIds = request.ArtifactIds;
db.Delete<AlbumArtifact>(x => artifactIds.Contains(x.ArtifactId));
db.Delete<ArtifactReport>(x => artifactIds.Contains(x.ArtifactId));
db.Delete<ArtifactLike>(x => artifactIds.Contains(x.ArtifactId));
db.Delete<Artifact>(x => x.CreativeId == request.Id);
db.Delete<CreativeArtist>(x => x.CreativeId == request.Id);
db.Delete<CreativeModifier>(x => x.CreativeId == request.Id);
db.Delete<Creative>(x => x.Id == request.Id);
}
}
Other databases should use its named connection for its named worker, e.g:
[Worker(Databases.Search)]
public class DeleteSearchCommand(IDbConnectionFactory dbFactory)
: SyncCommand<DeleteSearch>
{
protected override void Run(DeleteSearch request)
{
using var db = dbFactory.Open(Databases.Search);
db.DeleteById<ArtifactFts>(request.Id);
//...
}
}
Where it will be executed within its Database Lock.
Executing Commands
Now everytime the commands are executed they will be added to a ConcurrentQueue where they'll be serially executed by the worker's Background Task:
public class MyServices(IBackgroundJobs jobs) : Service
{
public void Any(DeleteCreative request)
{
// Queues a durable job to execute the command with the named worker
var jobRef = jobs.EnqueueCommand<DeleteCreativeCommand>(request);
// Returns immediately with a reference to the Background Job
}
public async Task Any(DeleteSearch request)
{
// Executes a transient (i.e. non-durable) job with the named worker
var result = await jobs.RunCommandAsync<DeleteSearchCommand>(request);
// Returns after the command is executed with its result (if any)
}
}
When using any SyncCommand* base class, its execution still uses database locks
but any contention is alleviated as they're executed serially by a single worker thread.
AutoQuery Crud Database Write Locks
To avoid SQLite concurrency write exceptions all DB Writes should be executed within its database lock or a named worker. Including the auto-generated AutoQuery Crud APIs which will implicitly use Database Locks if the primary database is SQLite.
AutoQuery CRUD can also be explicitly configured to always be executed within Database Locks with:
services.AddPlugin(new AutoQueryFeature {
UseDatabaseWriteLocks = true
});
SQLite Web Apps
That's about it, by using any of the above techniques to guard against concurrent writes you can take advantage of the simplicity, value and performance benefits of SQLite in your Apps and utilize a solution like litestream.io for real-time replication of your SQLite databases to highly reliable managed storage.
SQLite's Checklist For Choosing The Right Database Engine covers the few situations when a traditional Client/Server RDBMS will be more appropriate.
The primary use-case would be when your App needs to be distributed across multiple App Servers as using SQLite essentially forces you into scaling up, which gets more appealing every year with hardware getting cheaper and faster and cheap hosting providers like hetzner.com where you can get bare metal 48 Core/96 vCore EPYC Servers with fast NVMe SSDs for €236 per month - a fraction of the cost of comparable performance with any cloud managed solution

Which is a fraction of what it would cost for comparable performance using cloud managed databases:
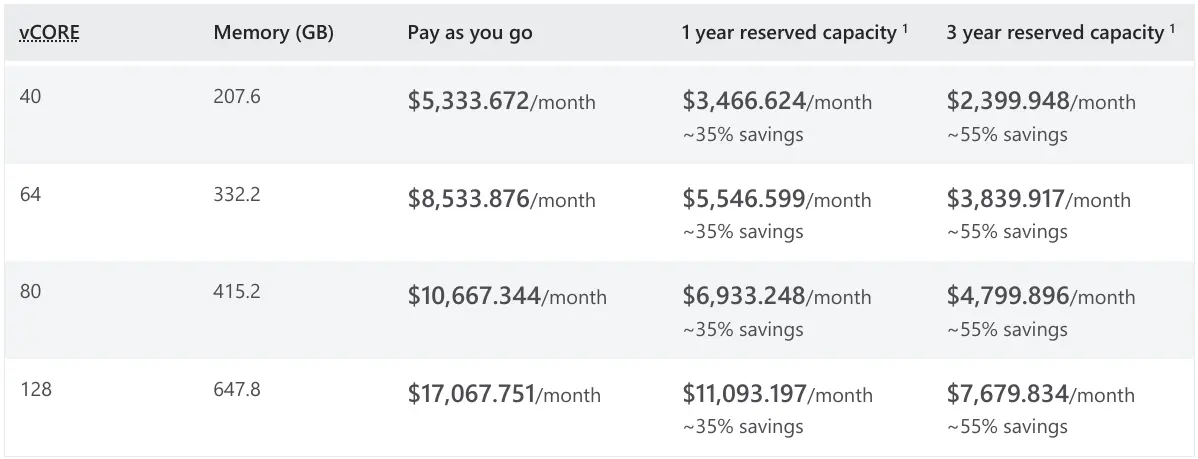
In the rare cases where you need to scale beyond a single server you'll initially be able to scale out your different App databases onto different servers.
Beyond that, if your App permits you may be able to adopt a multi-tenant architecture like Bluesky Social with each tenant having their own SQLite database to effectively enable infinite scaling.
For further info on using high performance SQLite in production web apps check out @aarondfrancis comprehensive website and course at highperformancesqlite.com - which contains a lot of great content accessible for free.
Example SQLite Apps
Our confidence in SQLite being the best choice for many web applications has led us to adopt it to power our latest web applications which are all deployed to a shared Hetzner VM whose inexpensive hosting costs allows us to host and make them available for free!
All projects are open-source and employ the different techniques detailed above that should serve as a great resource of how they're used in real-world Web Applications:
Blazor Diffusion
Generate images for free using custom Civit AI and FLUX-schnell models:
- Website: blazordiffusion.com
- GitHub: github.com/NetCoreApps/BlazorDiffusionVue
pvq.app
An OSS alternative to StackOverflow which uses the best proprietary and OSS Large Language Models to answer your technical questions. pvq.app is populated with over 1M+ answers for the highest rated StackOverflow questions - checkout pvq.app/leaderboard to find the best performing LLM models (results are surprising!)
- Website: pvq.app
- GitHub: github.com/ServiceStack/pvq.app
AI Server
The independent Microservice used to provide all AI Features used by the above applications. It's already been used to execute millions of LLM and Comfy UI Requests to generate Open AI Chat Answers and Generated Images used to populate the blazordiffusion.com and pvq.app websites.
It was the project used to develop and test Background Jobs in action where it serves as a private gateway to process all LLM, AI and image transformations requests that any of our Apps need where it dynamically delegates requests across multiple Ollama, Open AI Chat, LLM Gateway, Comfy UI, Whisper and ffmpeg providers.
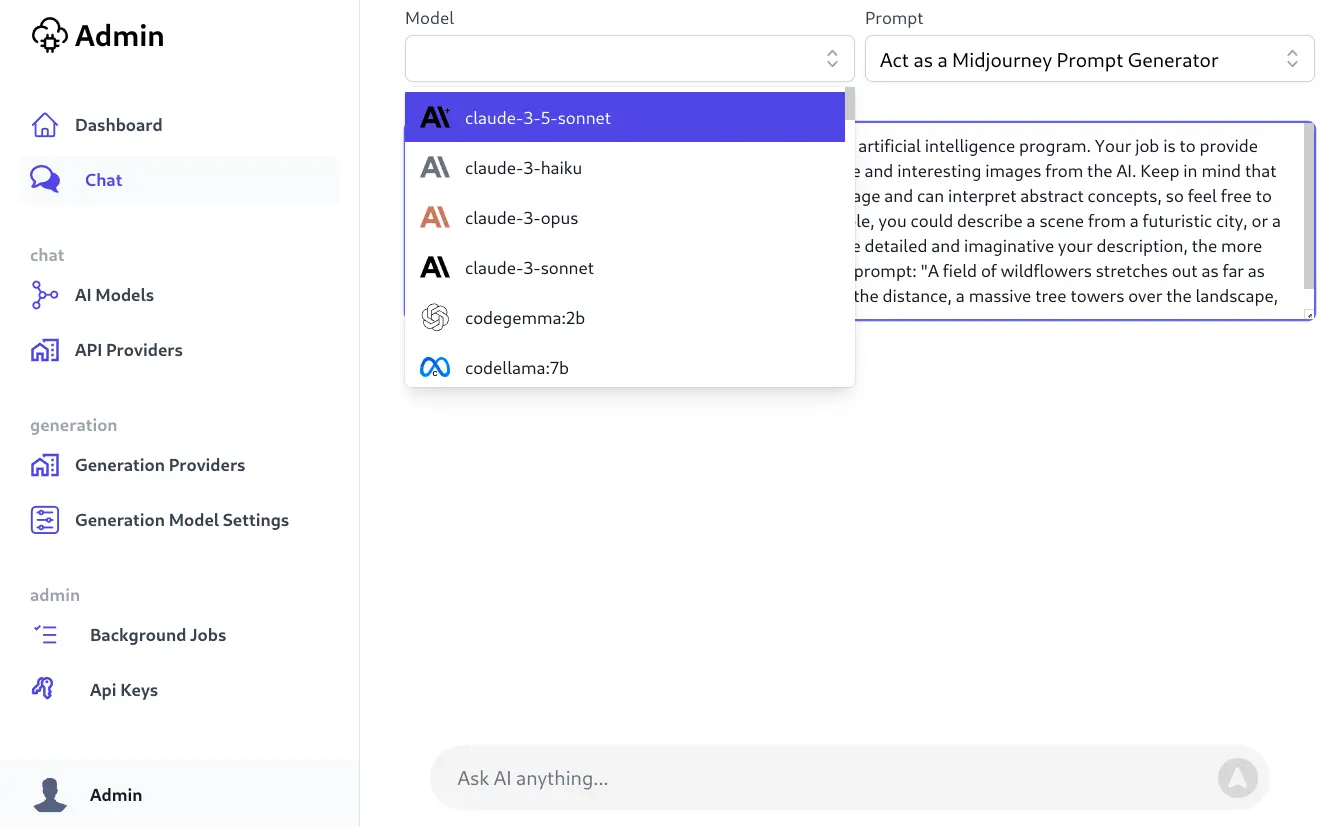
- Website: openai.servicestack.net
- GitHub: github.com/ServiceStack/ai-server
In addition to maintaining a history of AI Requests, it also provides file storage for its CDN-hostable AI generated assets and on-the-fly, cacheable image transformations.
Private AI Gateway
We're developing AI Server as a Free OSS Product that runs as a single Docker Container Microservice that Admins can use its built-in UIs to add multiple Ollama instances, Open AI Gateways to execute LLM requests and Client Docker agents installed with Comfy UI, ffmpeg and Whisper to handle all other non-LLM Requests.
Multiple Ollama, Open AI Gateway and Comfy UI Agents
The AI Server Docker container itself wont require any infrastructure dependencies or specific hardware requirements, however any Ollama endpoints or Docker Comfy UI Agents added will need to run on GPU-equipped servers.
Native end-to-end Typed Integrations to most popular languages
ServiceStack's Add ServiceStack Reference feature is used to provide native typed integrations to C#, TypeScript, JavaScript, Python, PHP, Swift, Java, Kotlin, Dart, F# and VB.NET projects which organizations can drop into their heterogeneous environments to manage their private AI Services used across their different Apps.
Protected Access with API Keys
AI Server utilizes Simple Auth with API Keys letting Admins create and distribute API Keys to only allow authorized clients to access their AI Server's APIs, which can be optionally further restricted to only allow access to specific APIs.
Active Development
AI Server is still actively developed whilst we finish adding support for different AI Requests in its first V1 release, including:
Large Language Models
- Open AI Chat
- Support for Ollama endpoints
- Support for Open Router, Open AI, Mistral AI, Google and Groq API Gateways
Comfy UI Agent / Replicate / DALL-E 3
- Text to Image
Comfy UI Agent
- Image to Image
- Image Upscaling
- Image with Mask
- Image to Text
- Text to Audio
- Text to Speech
- Speech to Text
ffmpeg
- image/video/audio format conversions
- image/video scaling
- image/video cropping
- image/video watermarking
- video trimming
Managed File Storage
- Blob Storage - isolated and restricted by API Key
V1 Release
We'll announce V1 after we've finished implementing the above AI Features with any necessary Admin UIs, feature documentation / API Docs and have streamlined the Server Install / Client Setup experience. After V1 we'll be happy to start accepting any external contributions for other AI Features users would like AI Server to support.
To get notified when AI Server is ready for public consumption, follow @ServiceStack or join our ~Quarterly Newsletter.
In the meantime you can reach us at ServiceStack/Discuss with any AI Server questions.