We've happy to announce several big ticket features in this release adding an exciting suite of functionality across the ServiceStack board!
Introducing AutoQuery Data!
ServiceStack's AutoQuery feature already provides the most productive way to create lightweight, high-performance data-driven Services which are able to naturally benefit from ServiceStack's wider rich, value-added ecosystem and thanks to OrmLite's typed RDBMS-agnostic API, AutoQuery has been used to create fully-queryable Services for most major RDBMS's.
Whilst AutoQuery is optimized around server-side SQL querying of Relational Databases, we also wanted to adopt its productive dev model and open it up to allow rich querying of other Data Sources as well - which we're happy to announce is now possible with AutoQuery Data!
Learn Once, Query Everywhere :)
AutoQuery Data is a new implementation that closely follows the dev model you're used to with AutoQuery where any experience gained in creating RDBMS AutoQuery Services previously are now also applicable to Querying alternative data sources as well where all features except for the RDBMS-specific Joining Tables and Raw SQL Filters features also have an equivalent in AutoQuery Data as well.
Like AutoQuery you can declaratively create AutoQuery Data Services using just Request DTO's but instead of
inheriting from QueryBase<T> you'd instead inherit from QueryData<T>, e.g:
//AutoQuery RDBMS
public class QueryCustomers : QueryBase<Customer> {}
//AutoQuery Data - Multiple / Open Data Sources
public class QueryCustomers : QueryData<Customer> {}
The API to call and consume both RDBMS AutoQuery and AutoQuery Data Services are indistinguishable to
external clients where both are queried using the same
implicit and
explicit conventions
and both return the same QueryResponse<T> Response DTO.
Use AutoQuery Viewer
A direct result of this means you can reuse AutoQuery Viewer (announced in the previous release) to access a rich auto UI for querying all AutoQuery implementations together in the same UI, whether queries are served from an RDBMS or an alternative data source.
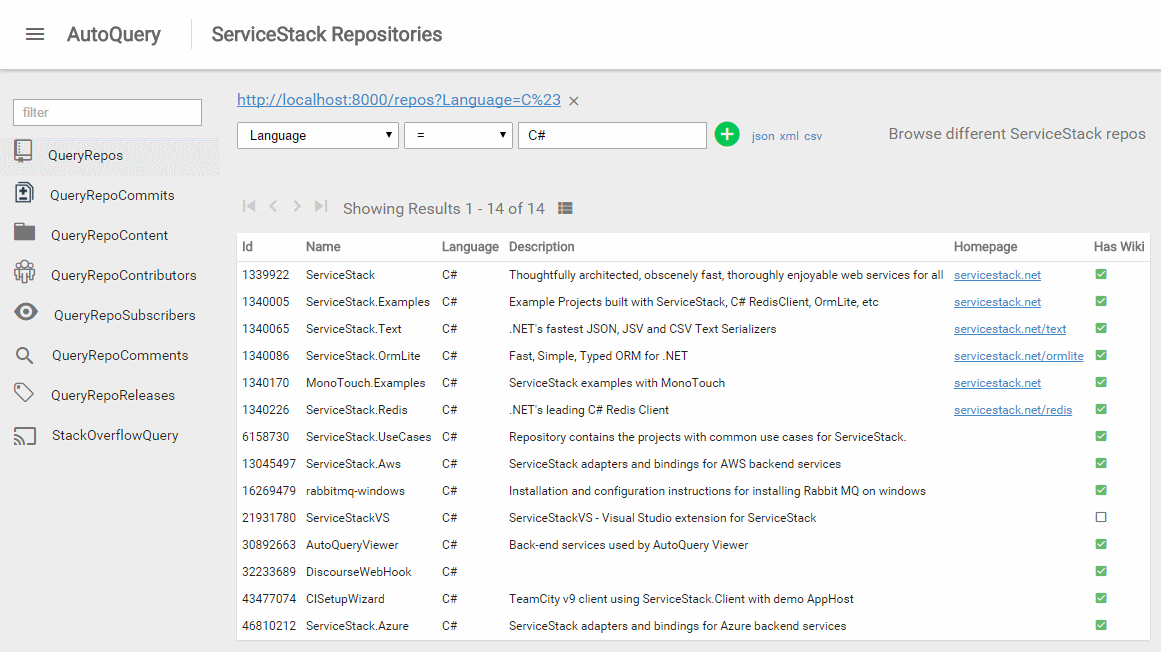
AutoQuery Data Sources
AutoQuery Data supports an Open Data provider model requiring an extra piece of configuration Services
need to function - the Data Source that it will query. Data Sources are registered with the
AutoQueryDataFeature plugin by calling using its fluent AddDataSource() API to register all Data Sources
you want available to query.
At launch there are 3 different data sources that are available - all of which are accessible as
extension methods on the QueryDataContext parameter for easy discoverability:
Plugins.Add(new AutoQueryDataFeature()
.AddDataSource(ctx => ctx.MemorySource(...))
.AddDataSource(ctx => ctx.ServiceSource(...))
.AddDataSource(ctx => ctx.DynamoDBSource(...))
);
Memory Data Source
The simplest data source we can query is an in-memory .NET collection registered with ctx.MemorySource().
But how the collection is populated remains up to you. The example below shows registering collections from
multiple sources inc. in-line code, populated from a CSV file (utilizing ServiceStack's new
CSV deserialization support) and populated from a 3rd Party API using
HTTP Utils:
//Declaration in code
var countries = new[] {
new Country { ... },
new Country { ... },
};
//From CSV File
List<Currency> currencies = File.ReadAllText("currencies.csv").FromCsv<List<Currency>>();
//From 3rd Party API
List<GithubRepo> repos = "https://api.github.com/orgs/ServiceStack/repos"
.GetJsonFromUrl(req => req.UserAgent="AutoQuery").FromJson<List<GithubRepo>>();
//AutoQuery Data Plugin
Plugins.Add(new AutoQueryDataFeature { MaxLimit = 100 }
.AddDataSource(ctx => ctx.MemorySource(countries))
.AddDataSource(ctx => ctx.MemorySource(currencies))
.AddDataSource(ctx => ctx.MemorySource(repos))
);
After data sources are registered, you can then create AutoQuery Data Services to query them:
[Route("/countries")]
public class QueryCountries : QueryData<Country> {}
[Route("/currencies")]
public class QueryCurrencies : QueryData<Currency> {}
[Route("/repos")]
public class QueryGithubRepos : QueryData<GithubRepo> {}
With just the empty Request DTO's above they're now queryable like any other AutoQuery Service, e.g:
- /countries?code=AU
- /currencies.json?code=AUD
- /repos.csv?watchers_count>=100&orderBy=-watchers_count,name&fields=name,homepage,language
Cacheable Data Sources
The examples above provides a nice demonstration of querying static memory collections. But Data Sources offers even more flexibility where you're also able to query and cache dynamic .NET collections that are customizable per-request.
The registration below shows an example of this where results are dynamically fetched from GitHub's API and persisted in the local in-memory cache for 5 minutes - throttling the number of requests made to the external 3rd Party API:
.AddDataSource(ctx => ctx.MemorySource(() =>
$"https://api.github.com/repos/ServiceStack/{ctx.Request.GetParam("repo")}/contributors"
.GetJsonFromUrl(req => req.UserAgent="AutoQuery").FromJson<List<GithubContributor>>(),
HostContext.LocalCache,
TimeSpan.FromMinutes(5)
));
We can now create an AutoQuery Data Service to query the above cached GithubContributor Memory Source:
[Route("/contributors")]
public class QueryContributors : QueryData<GithubContributor>
{
public string Repo { get; set; }
}
Thanks to the Typed Request DTO we also get an end-to-end Typed API for free which we can use to query the contributors result-set returned from GitHub's API. As an example we can view the Top 20 Contributors for the ServiceStack Project with:
var top20Contributors = client.Get(new QueryContributors {
Repo = "ServiceStack",
OrderByDesc = "Contributions",
Take = 20
});
top20Contributors.PrintDump(); // Pretty print results to Console
Service Data Source
The next step in querying for even richer result-sets, whether you want to add custom validation, access multiple dependencies, construct complex queries or other custom business logic, you can use a Service Source instead which lets you call a Service and use its Response as the dynamic Data Source that you can apply Auto Querying logic on.
ServiceSource is very similar to MemorySource however instead of passing in the in-memory collection
you want to query directly, you'll need to pass a Request DTO of the Service you want called instead.
The response of the Service is then further queried just as if its results were passed into a MemorySource
directly.
We'll illustrate with a few examples how to register and use ServiceSources, explore some of their capabilities and provide some examples of when you may want to use them below.
The UserLogin ServiceSouce shows you can just pass an empty Request DTO as-is to execute its Service.
The RockstarAlbum and GithubRepo Service Sources are however leveraging the built-in
Auto Mapping to copy any matching
properties from the AutoQuery Request DTO to the downstream GetRockstarAlbums and GetGithubRepos
Request DTO's. Finally the responses for the GithubRepo Service is cached for 5 minutes so any
subsequent matching requests end up querying the cached result set instead of re-executing the GetGithubRepos
Service:
Plugins.Add(new AutoQueryDataFeature { MaxLimit = 100 }
.AddDataSource(ctx => ctx.ServiceSource<UserLogin>(new GetTodaysUserActivity())),
.AddDataSource(ctx => ctx.ServiceSource<RockstarAlbum>(ctx.Dto.ConvertTo<GetRockstarAlbums>())),
.AddDataSource(ctx => ctx.ServiceSource<GithubRepo>(ctx.Dto.ConvertTo<GetGithubRepos>(),
HostContext.Cache, TimeSpan.FromMinutes(5)));
);
The implementation of GetTodaysUserActivity Service uses an async OrmLite RDBMS call to get all User Logins
within the last day, fetches the Live Activity data from Redis, then
merges the disconnected POCO result sets
into the UserLogin POCO which it returns:
[Route("/useractivity/today")]
public class QueryTodaysUserActivity : QueryData<User> {}
public async Task<List<UserLogin>> Any(GetTodaysUserActivity request)
{
var logins = await Db.SelectAsync<UserLogin>(x => x.LastLogin >= DateTime.UtcNow.AddDays(-1));
var activities = Redis.As<Activity>().GetAll();
logins.Merge(activities);
return logins;
}
The GetRockstarAlbums Service shows an example of a calling an existing ad hoc DB Service executing an
arbitrary custom Query. It uses the Request DTO Auto-Mapping at the ServiceSource registration to
first copy any matching properties from the initial QueryRockstarAlbums Request DTO to populate a new
GetRockstarAlbums instance which is what's used to execute the Service with.
In this way the QueryRockstarAlbums AutoQuery Service is essentially decorating the underlying
GetRockstarAlbums Service giving it access to AutoQuery features where clients are able to apply
further post-querying server logic to an existing Service implementation which now lets them filter,
sort, select only a partial list of fields, include additional aggregate queries, etc.
public class QueryRockstarAlbums : QueryData<RockstarAlbum>
{
public string Name { get; set; }
public int[] IdBetween { get; set; }
}
public object Any(GetRockstarAlbums request)
{
var q = Db.From<RockstarAlbum>();
if (request.IdBetween != null)
q.Where(x => x.Id >= request.IdBetween[0] && x.Id <= request.IdBetween[1]);
if (request.Name != null)
q.Where(x => x.Name == request.Name);
return new GetRockstarAlbumsResponse { Results = Db.Select(q) };
}
One thing to notice is that ServiceSource still works whether the results are wrapped in a Response DTO
instead of a naked IEnumerable<RockstarAlbum> collection. This is transparently supported as ServiceSource
will use the first matching IEnumerable<T> property for Services that don't return a collection.
It should be noted that decorating an existing OrmLite Service is rarely necessary as in most cases you'll be able to get by with just a simple AutoQuery RDBMS query as seen in the Service below which replaces the above 2 Services:
public class QueryRockstarAlbums : QueryDb<RockstarAlbum> {}
The final GetGithubRepos ServiceSource example shows an example of a slightly more complex implementation
than a single 3rd Party API call where it adds custom validation logic and call different 3rd Party API
Endpoints depending on user input:
public class QueryGithubRepo : QueryData<GithubRepo>
{
public string User { get; set; }
public string Organization { get; set; }
}
public object Get(GetGithubRepos request)
{
if (request.User == null && request.Organization == null)
throw new ArgumentNullException("User");
var url = request.User != null
? "https://api.github.com/users/{0}/repos".Fmt(request.User)
: "https://api.github.com/orgs/{0}/repos".Fmt(request.Organization);
return url.GetJsonFromUrl(requestFilter:req => req.UserAgent = GetType().Name)
.FromJson<List<GithubRepo>>();
}
A hidden feature ServiceSources are naturally able to take advantage of due to its behind-the-scenes usage
of the new ServiceGateway (announced later) is that the exact code above could still function if the
QueryGithubRepo AutoQuery Data Service and underlying GetGithubRepos Service were moved to different
hosts :)
Custom AutoQuery Data Implementation
Just like you can
Create a Custom implementation
in AutoQuery, you can do the same in AutoQuery Data by just defining an implementation for your AutoQuery
Data Request DTO. But instead of IAutoQueryDb you'd reference the IAutoQueryData dependency to construct
and execute your custom AutoQuery Data query.
When overriding the default implementation of an AutoQuery Data Service you also no longer need to register
a Data Source as you can specify the Data Source in-line when calling AutoQuery.CreateQuery().
For our custom AutoQuery Data implementation we'll look at creating a useful Service which reads the
daily CSV Request and Error Logs from the new CsvRequestLogger (announced later) and queries it by
wrapping the POCO RequestLogEntry results into a MemoryDataSource:
[Route("/query/requestlogs")]
[Route("/query/requestlogs/{Date}")]
public class QueryRequestLogs : QueryData<RequestLogEntry>
{
public DateTime? Date { get; set; }
public bool ViewErrors { get; set; }
}
public class CustomAutoQueryDataServices : Service
{
public IAutoQueryData AutoQuery { get; set; }
public object Any(QueryRequestLogs query)
{
var date = query.Date.GetValueOrDefault(DateTime.UtcNow);
var logSuffix = query.ViewErrors ? "-errors" : "";
var csvLogsFile = VirtualFileSources.GetFile("requestlogs/{0}-{1}/{0}-{1}-{2}{3}.csv".Fmt(
date.Year.ToString("0000"),
date.Month.ToString("00"),
date.Day.ToString("00"),
logSuffix));
if (csvLogsFile == null)
throw HttpError.NotFound("No logs found on " + date.ToShortDateString());
var logs = csvLogsFile.ReadAllText().FromCsv<List<RequestLogEntry>>();
var q = AutoQuery.CreateQuery(query, Request,
db: new MemoryDataSource<RequestLogEntry>(logs, query, Request));
return AutoQuery.Execute(query, q);
}
}
This Service now lets you query the Request Logs of any given day, letting you filter, page and sort through the Request Logs of the day. While we're at it, let's also create multiple Custom AutoQuery Data implementations to act as canonical smart links for the above Service:
[Route("/logs/today")]
public class TodayLogs : QueryData<RequestLogEntry> { }
[Route("/logs/today/errors")]
public class TodayErrorLogs : QueryData<RequestLogEntry> { }
[Route("/logs/yesterday")]
public class YesterdayLogs : QueryData<RequestLogEntry> { }
[Route("/logs/yesterday/errors")]
public class YesterdayErrorLogs : QueryData<RequestLogEntry> { }
The implementations of which just delegates to QueryRequestLogs with the selected Date and whether or
not to show just the error logs:
public object Any(TodayLogs request) =>
Any(new QueryRequestLogs { Date = DateTime.UtcNow });
public object Any(TodayErrorLogs request) =>
Any(new QueryRequestLogs { Date = DateTime.UtcNow, ViewErrors = true });
public object Any(YesterdayLogs request) =>
Any(new QueryRequestLogs { Date = DateTime.UtcNow.AddDays(-1) });
public object Any(YesterdayErrorLogs request) =>
Any(new QueryRequestLogs { Date = DateTime.UtcNow.AddDays(-1), ViewErrors = true });
And with no more effort we can jump back to /ss_admin/ and use AutoQuery Viewer's nice UI to quickly
inspect Todays and Yesterdays Request and Error Logs :)
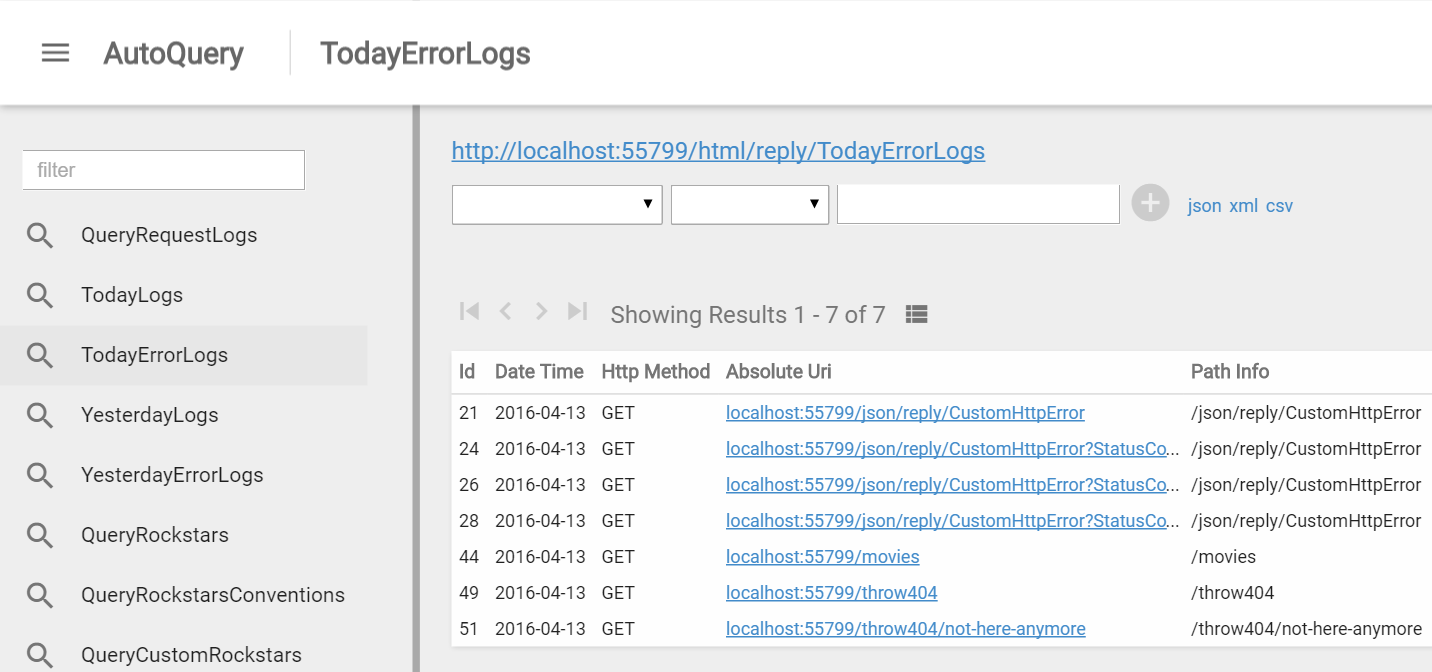
DynamoDB Data Source!
Probably the most exciting Data Source available is DynamoDbSource as it provides the most productive
development experience for effortlessly creating rich, queryable and optimized Services for DynamoDB data stores!

DynamoDB is the near perfect solution if you're on AWS and in need of a managed NoSQL data storage solution that can achieve near-infinite scale whilst maintaining constant single-digit millisecond performance. The primary issue with DynamoDB however is working with it's unstructured schema and API's which is reflected in the official .NET DynamoDB client providing a flexible but low-level and cumbersome development experience to work with directly. Most of these shortcomings are resolved with our POCO-friendly PocoDynamo client which provides an intuitive and idiomatic Typed .NET API that lets you reuse your DTO's and OrmLite POCO Data Models for persistence in DynamoDB.
Querying in DynamoDB is even more cumbersome, unlike an RDBMS which can process ad hoc queries on non-indexed fields with decent performance, every query in DynamoDB needs to be performed on an index defined ahead-of-time. Any queries not on an index needs to be sent as a Filter Expression and even more limiting is that queries can only be executed against rows containing the same hash id. If you need to query data spanning across multiple hash ids you either need to create a separate Global Index or perform a full SCAN operation which is even slower than full table scans on an RDBMS as they need to be performed on all underlying sharded nodes which can quickly eat up your reserved provisioned throughput allotted to your DynamoDB table.
Optimal DynamoDB Queries
With AutoQuery's DynamoDbSource a lot of these nuances are transparently handled where it will automatically
create the most optimal DynamoDB Query based on the fields populated on the incoming AutoQuery Request DTO.
E.g. it will perform a
DynamoDB Query
when the Hash field is populated otherwise transparently falls back into a
Scan Operation.
Any conditions that query an Index field are added to the
Key Condition,
starting first with the Range Key (if specified), otherwise uses any populated Local Indexes it can
find before any of the remaining conditions are added to the
Filter Expression.
Transparently adopting the most optimal queries dramatically reduces development time as it lets you quickly create, change and delete DynamoDB Services without regard for Indexes where it will often fallback to SCAN operations (performance of which is unnoticeable during development). Then once you're project is ready to deploy to production, go back and analyze all remaining queries your System relies on at the end then re-create tables with the appropriate indexes so that all App queries are efficiently querying an index.
When needed you can specify
.DynamoDbSource<T>(allowScans:false)to disable anyone from executing SCAN requests when deployed to production.
Simple AutoQuery Data Example
To illustrate how to use AutoQuery with DynamoDB we'll walk through a simple example of querying Rockstars Albums. For this example we'll specify explicit conventions so we can use ServiceStack's typed .NET Service Clients to show which fields we're going to query and also lets us call the Service with a convenient typed API:
[Route("/rockstar-albums")]
public class QueryRockstarAlbums : QueryData<RockstarAlbum>
{
public int? Id { get; set; } // Primary Key | Range Key
public int? RockstarId { get; set; } // Foreign key | Hash Key
public string Name { get; set; }
public string Genre { get; set; }
public int[] IdBetween { get; set; }
}
Here we see that creating DynamoDB Queries is no different to any other AutoQuery Data Service, where the
same definition is used irrespective if the data source was populated from a MemorySource, ServiceSource
or DynamoDbSource and the only thing that would need to change to have it query an RDBMS instead is the
QueryDb<T> base class.
The text in comments highlight that when the RockstarAlbum POCO is stored in an RDBMS
OrmLite
creates the table with the Id as the Primary Key and RockstarId as a Foreign Key to the Rockstar table.
This is different in DynamoDB where
PocoDynamo behavior is to keep related records together so
they can be efficiently queried and will instead Create the RockstarAlbum DynamoDB Table with the
RockstarId as the Hash Key and its unique Id as the Range Key.
Register DynamoDbSource
To use DynamoDB AutoQuery's you need to first configure
PocoDynamo
which is just a matter of passing an an initialized AmazonDynamoDBClient and telling PocoDynamo which
DynamoDB tables you intend to use:
container.Register(c => new PocoDynamo(new AmazonDynamoDBClient(...))
.RegisterTable<Rockstar>()
.RegisterTable<RockstarAlbum>()
);
Then before using PocoDynamo, call InitSchema() to tell it to automatically go through and create all
DynamoDB Tables that were registered but don't yet exist in DynamoDB:
var dynamo = container.Resolve<IPocoDynamo>();
dynamo.InitSchema();
So the first time InitSchema() is run it will create both Rockstar and RockstarAlbum tables but will
no longer create any tables on any subsequent runs. After InitSchema() has completed we're assured that
both Rockstar and RockstarAlbum tables exist so we can start using PocoDynamo's typed APIs to populate
them with Data:
dynamo.PutItems(new Rockstar[] { ... });
dynamo.PutItems(new RockstarAlbum[] { ... });
Behind the scenes PocoDynamo efficiently creates the minimum number of BatchWriteItem requests as necessary to store all Rockstar and RockstarAlbum's.
Now that we have data we can query we can register the AutoQuery Data plugin along with the Rockstar
and RockstarAlbum DynamoDB Tables we want to be able to query:
Plugins.Add(new AutoQueryDataFeature { MaxLimit = 100 }
.AddDataSource(ctx => ctx.DynamoDbSource<Rockstar>())
.AddDataSource(ctx => ctx.DynamoDbSource<RockstarAlbum>())
);
RockstarAlbum POCO Table Definition
Where RockstarAlbum is just a simple POCO and can be used as-is throughout all of ServiceStack's libraries
inc. OrmLite, Redis, Caching Providers, Serializers, etc:
public class RockstarAlbum
{
[AutoIncrement]
public int Id { get; set; }
[References(typeof(Rockstar))]
public int RockstarId { get; set; }
[Index]
public string Genre { get; set; }
public string Name { get; set; }
}
PocoDynamo uses the same generic metadata attributes in ServiceStack.Interfaces as OrmLite.
When this POCO is created in OrmLite it creates:
- A
RockstarAlbumtable with anIdauto incrementing Primary Key - The
RockstarIdas the Foreign Key for theRockstartable - Adds an Index on the
Genrecolumn.
Whereas in DynamoDB, PocoDynamo creates:
- The
RockstarAlbumtable with theIdas an auto incrementing Range Key - The
RockstarIdas the Hash Key - Creates a Local Secondary Index for the Genre attribute.
Typed AutoQuery DynamoDB Queries
Since the properties we want to query are explicitly typed we can make use of ServiceStack's nice typed Service Client API's to call this Service and fetch Kurt Cobains Grunge Albums out of the first 5 recorded:
var response = client.Get(new QueryRockstarAlbums { //QUERY
RockstarId = kurtCobainId, //Key Condition
IdBetween = new[]{ 1, 5 }, //Key Condition
Genre = "Grunge", //Filter Condition
});
response.PrintDump(); // Pretty print results to Console
As illustrated in the comments, DynamoDB AutoQuery performs the most efficient DynamoDB Query required in
order to satisfy this request where it will create a
Query Request
with the RockstarId and IdBetween conditions added to the Key Condition and the remaining Genre
added as a Filter Expression.
If we instead wanted to fetch all of Kurt Cobains Grunge Albums where there was no longer a condition on
the Album Id Range Key, i.e:
var response = client.Get(new QueryRockstarAlbums { //QUERY
RockstarId = kurtCobainId, //Key Condition
Genre = "Grunge", //Key Condition
});
It would instead create a Query Request configured to use the Genre Local Secondary Index and have
added both RockstarId Hash Key and index Genre to the Key Condition.
But if you instead wanted to view all Grunge Albums, i.e:
var response = client.Get(new QueryRockstarAlbums { //SCAN
Genre = "Grunge" //Filter Condition
});
As no Hash Key was specified it would instead create a SCAN Request where as there's no index, it adds all conditions to the Filter Expression.
AutoQuery DynamoDB Global Index Queries
For times when you need to perform an efficient Query Request across multiple hash keys you will need to create a Global Secondary Index. Luckily this is easy to do in PocoDynamo where you can define Global Indexes with a simple POCO class definition:
public class RockstarAlbumGenreIndex : IGlobalIndex<RockstarAlbum>
{
[HashKey]
public string Genre { get; set; }
[RangeKey]
public int Id { get; set; }
public string Name { get; set; } // projected property
public int RockstarId { get; set; } // projected property
}
Global Indexes can be thought of as "automatically synced tables" specified with a different Hash Key. Just like DynamoDB tables you can specify the Hash Key you want to globally query and create the Index on as well as a separate Range Key you want to be able to perform efficient Key Condition queries on. You'll also want to specify any properties you want returned when querying the Global Index so they'll be automatically projected and stored with the Global Index, ensuring fast access.
Then to have PocoDynamo create the Global Index it should be referenced on the table the Global Index is on:
[References(typeof(RockstarAlbumGenreIndex))]
public class RockstarAlbum { ... }
When referenced, InitSchema() will create the RockstarAlbumGenreIndex Global Secondary Index when it
creates the RockstarAlbum DynamoDB Table.
With the Global Index created we can now query it just like we would any other DynamoDB AutoQuery but instead of querying a table, we query the Index instead:
public class QueryRockstarAlbumsGenreIndex : QueryData<RockstarAlbumGenreIndex>
{
public string Genre { get; set; } // Hash Key
public int[] IdBetween { get; set; } // Range Key
public string Name { get; set; }
}
Once defined you can query it just like any other AutoQuery Service where you're now able to perform efficient queries by Genre across all Rockstar Album's:
var response = client.Get(new QueryRockstarAlbumsGenreIndex //QUERY
{
Genre = "Grunge", //Key Condition
IdBetween = new[] { 1, 1000 }, //Key Condition
});
Custom POCO Result Mappings
A noticeable difference from querying a Global Index instead of the Table directly is that results are
returned in a different RockstarAlbumGenreIndex POCO. Luckily we can use AutoQuery's
Custom Results Feature
to map the properties back into the original table RockstarAlbum with:
public class QueryRockstarAlbumsGenreIndex : QueryData<RockstarAlbumGenreIndex,RockstarAlbum>
{
public string Genre { get; set; }
public int[] IdBetween { get; set; }
public string Name { get; set; }
}
Now when we query the Index we get our results populated in RockstarAlbum DTO's instead:
QueryResponse<RockstarAlbum> response = client.Get(new QueryRockstarAlbumsGenreIndex
{
Genre = "Grunge", //Key Condition
IdBetween = new[] { 1, 1000 }, //Key Condition
});
Caching AutoQuery Services
One of the many benefits of AutoQuery Services being just regular ServiceStack Services is that we get
access to ServiceStack's rich ecosystem of enhanced functionality around existing Services. An example added
in this release is ServiceStack's new HTTP Caching feature which lets you easily cache a Service with
the new [CacheResponse] attribute, letting you declaratively specify how long you want to cache identical
requests for on the Server as well as a MaxAge option for instructing the Client how long they should
consider their local cache is valid for and any custom Cache-Control behavior you want them to have, e.g:
[Route("/rockstar-albums")]
[CacheResponse(Duration = 60, MaxAge = 30, CacheControl = CacheControl.MustRevalidate)]
public class QueryRockstarAlbums : QueryData<RockstarAlbum>
{
public int? Id { get; set; }
public int? RockstarId { get; set; }
public string Genre { get; set; }
public int[] IdBetween { get; set; }
}
So with just the above single Request DTO we've declaratively created a fully-queryable DynamoDB AutoQuery
Service that transparently executes the most ideal DynamoDB queries for each request, has it's optimal
representation efficiently cached on both Server and clients, whose Typed DTO can be reused as-is on the
client to call Services with an end-to-end Typed API using any
.NET Service Client,
that's also available to external developers in a clean typed API, natively in their preferred language of
choice, accessible with just a right-click menu integrated inside VS.NET, Xcode, Android Studio, IntelliJ
and Eclipse - serving both PCL Xamarin.iOS/Android as well as native iOS and Android developers by just
Adding a ServiceStack Reference
to the base URL of a remote ServiceStack Instance - all without needing to write any implementation!
More Info
For more examples exploring different AutoQuery Data features checkout the AutoQuery Data Tests and AutoQuery DynamoDB Tests that can be compared on a feature-by-feature basis against the existing AutoQuery Tests they were originally based on.
AutoQuery Breaking Changes
As there are now 2 independent AutoQuery implementations we felt it necessary to rename the existing AutoQuery
Types to establish a clear naming convention making it obvious which implementation the different Types are for.
Types that are specific to the existing RDBMS AutoQuery now starts with QueryDb* whereas equivalent
Types for AutoQuery Data start with QueryData*. The decorated example below shows an example of
these differences:
//AutoQuery RDBMS
[QueryDb(QueryTerm.Or)]
public class QueryCustomers : QueryDb<Customer>
{
[QueryDbField(Term = QueryTerm.Or, Operand = ">=", Field = "LastName")]
public int? OrAgeOlderThan { get; set; }
}
public class AutoQueryRDBMSServices(IAutoQueryDb autoQuery) : Service
{
...
}
//AutoQuery Data - Multiple / Open Data Sources
[QueryData(QueryTerm.Or)]
public class QueryCustomers : QueryData<Customer>
{
[QueryDataField(Term = QueryTerm.Or, Condition = ">=", Field = "LastName")]
public int? OrAgeOlderThan { get; set; }
}
public class AutoQueryDataServices(IAutoQueryData autoQuery) : Service
{
...
}
For backwards compatibility we're continuing to support the most common usage for creating AutoQuery Services
that just inherit QueryBase<T>, but this is now deprecated in favor of QueryDb<T>. All other existing
[Query*] attributes will need to be renamed to [QueryDb*] as seen above, likewise IAutoQuery is also
deprecated and renamed to IAutoQueryDb. If in doubt please check any the deprecation message on types with
any build errors as they'll indicate the name of the new Type it should be renamed to.
We deeply regret any inconvenience these changes causes as we didn't foresee we'd extend AutoQuery Services to support multiple Data Sources beyond the RDBMS of which it was designed for. Introducing a clear naming convention now establishes a clear symmetry between both implementations which we expect to reduce a lot of confusion in future.
Other AutoQuery Features
Customizable Fields
AutoQuery's Customizable Fields received some improvements where the fields list are now case-insensitive, e.g:
?fields=columnA,COLUMNB
There's also now support for wildcards which let you quickly reference all fields on a table using the
table.* format, e.g:
?fields=id,departmentid,department,employee.*
Which is a shorthand that expands to manually listing each field in the Employee table, useful for queries
which joins multiple tables, e.g:
[Route("/employees", "GET")]
public class QueryEmployees : QueryDb<Employee>,
IJoin<Employee, EmployeeType>,
IJoin<Employee, Department>,
IJoin<Employee, Title>
{
//...
}
Exclude AutoQuery Collections from being initialized
The default configuration for all languages supported in Add ServiceStack Reference is to InitializeCollections which allows for a nicer client API in which clients can assume Request DTO's have their collections initialized allowing them to use the shorthand collection initializer syntax, e.g:
var response = client.Get(new SearchQuestions {
Tags = { "redis", "ormlite" }
});
A problem with this is that AutoQuery encourages having multiple collection properties, most of which will
remain unused but would still have an empty collection initialized for all unused properties that are then
emitted on the wire. To help with this we've made it easy to prevent collections from being emitted in
AutoQuery DTO's by configuring the pre-registered NativeTypesFeature plugin below with:
var nativeTypes = this.GetPlugin<NativeTypesFeature>();
nativeTypes.InitializeCollectionsForType = NativeTypesFeature.DontInitializeAutoQueryCollections;
HTTP Caching
Another big ticket feature we expect to prove extremely valuable is the improved story around HTTP Caching
that transparently improves the behavior of existing ToOptimized Cached Responses, provides a typed API to
to opt-in to HTTP Client features, introduces a simpler declarative API for enabling both
Server and Client Caching of Services and also includes Cache-aware clients that are able to improve the
performance and robustness of all existing .NET Service Clients - functionality that's especially valuable to
bandwidth-constrained Xamarin.iOS / Xamarin.Android clients offering improved performance and greater resilience.
The new caching functionality is encapsulated in the new HttpCacheFeature plugin that's pre-registered
by default and can be removed to disable the new HTTP Caching behavior with:
Plugins.RemoveAll(x => x is HttpCacheFeature);
Server Caching
To explain the new HTTP Caching features we'll revisit the ServiceStack's previous caching support which
enables what we refer to as Server Caching where the response of a Service is cached in the registered
Caching Provider
by calling the ToOptimizedResult* API's which lets you programmatically construct the Cache Key and/or
how long the cache should be persisted for, e.g:
public class OrdersService : Service
{
public object Any(GetCustomers request)
{
//Good candidates: request.ToGetUrl() or base.Request.RawUrl
var cacheKey = "unique_key_for_this_request";
var expireCacheIn = TimeSpan.FromHours(1);
return Request.ToOptimizedResultUsingCache(Cache, cacheKey, expireCacheIn,
() => {
//Delegate executed only if item doesn't already exist in cache
//Any response DTO returned is cached on subsequent requests
});
}
}
As the name indicates this stores the most optimal representation of the Service Response in the registered
ICacheClient, so for example if a client called the above API with Accept: application/json and
Accept-Encoding: deflate, gzip HTTP Request Headers ServiceStack would store the deflated serialized JSON
bytes in the Cache and on subsequent requests resulting in the same cache key would write the compressed
deflated bytes directly to the Response OutputStream - saving both CPU and bandwidth.
More Optimal OptimizedResults
But there's an even more optimal result we could return instead: Nothing :) and save even more CPU and bandwidth! Which is precisely what the HTTP Caching directives built into the HTTP spec allow for. To enable it you'd need to return additional HTTP Headers to the client containing the necessary metadata they can use to determine when their locally cached responses are valid. Typically this is the Last-Modified date of when the Response/Resource was last modified or an Entity Tag containing an opaque string the Server can use to determine whether the client has the most up-to-date response.
The most optimal cache validator we can use for existing ToOptimizedResult* API's is the Last Modified
date which is now being cached along with the response. An additional instruction we need to return to the
client is the
Cache-Control HTTP Response Header
which instructs the client what caching behavior to apply to the server response. As we want the new behavior
to work transparently without introducing caching issues to existing Services, we've opted for a conservative:
Cache-Control: max-age=0
Which tells the client to treat the server response as immediately stale and that it should send another request to the Server for identical requests, but this time the client will append a If-Modified-Since HTTP Request Header which ServiceStack now automatically looks up to determine if the cache the client has is valid. If no newer cache for this request has been created since, ServiceStack returns a 304 NotModified Response with an empty Request Body which tells the client it's safe to use their local cache instead.
Modify Cache-Control for OptimizedResults
You can change the Cache-Control Header returned for existing ToOptimizedResult responses by modifying
the pre-registered HttpCacheFeature, e.g:
var cacheFeature = this.GetPlugin<HttpCacheFeature>();
cacheFeature.CacheControlForOptimizedResults = "max-age=3600, must-revalidate";
This tells the client that they can treat their locally cached server responses as valid for 1hr
but after 1hr they must check back with the Server to determine if their cache is still valid.
HTTP Client Caching
The Caching features above revolve around enhancing existing Server Cached responses with HTTP Caching
features to further reduce latency and save CPU and bandwidth resources. In addition to Server Caching
pure stand-alone HTTP Caching features (i.e. that don't cache server responses) are now available as
first-class properties on HttpResult:
// Only one Cache Validator below needs to be specified:
string ETag // opaque string representing integrity of response
DateTime? LastModified // the last time the response was Modified
// Specify Client/Middleware Cache Behavior
TimeSpan? MaxAge // How long cached response is considered valid
CacheControl CacheControl // More options to specify Cache-Control behavior:
enum CacheControl {
None,
Public,
Private,
MustRevalidate,
NoCache,
NoStore,
NoTransform,
ProxyRevalidate,
}
// Available, but rarely used
TimeSpan? Age // Used by proxies to indicate how old cache is
DateTime? Expires // Less preferred alternative to MaxAge
We'll walk through a couple of real-world examples to show how we can make use of these new properties and explain the HTTP Caching behavior they enable.
Using ETags
The minimum properties required for HTTP Caching is to specify either an ETag or LastModified
Caching Validator. You can use any opaque string for the ETag that uniquely represents a version of the
response that you can use to determine what version the client has, which could be an MD5 or SHA Hash of
the response but can also be a unique version string. E.g. Adding a RowVersion property to your OrmLite
POCO Data Models turns on
OrmLite's Optimistic Concurrency
feature where each time a record is modified it's automatically populated with a new version, these
characteristics makes it ideal for use as an ETag which we can just return as a string:
public object Any(GetCustomer request)
{
var response = Db.SingleById<Customer>(request.Id);
return new HttpResult(response) {
ETag = response.RowVersion.ToString(),
};
}
Whilst this is the minimum info required in your Services, the client also needs to know how long the
cache is valid for as typically indicated by the MaxAge property. If it's omitted ServiceStack falls back
to use the HttpCacheFeature.DefaultMaxAge of 10 minutes which can be changed in your AppHost with:
this.GetPlugin<HttpCacheFeature>().DefaultMaxAge = TimeSpan.FromHours(1);
So the HTTP Response Headers the client receives when calling this Service for the first time is something similar to:
ETag: "42"
Cache-Control: max-age=600
Which tells the client that they can use their local cache for identical requests issued within the next 10 minutes. After 10 minutes the cache is considered stale and the client will issue a new request to the server but this time it will include the ETag it has associated with the Response, i.e:
If-None-Match: "42"
When this happens the Service is still executed as normal and if the Customer hasn't changed, the
HttpCacheFeature will compare the HttpResult.ETag response with the clients ETag above and if they
match ServiceStack will instead return a 304 NotModified with an Empty Response Body to indicate to the
client that it can continue to use their locally cached response.
So whilst using a HttpResult doesn't cache the response on the Server and save further resources
used in executing the Service, it still benefits from allowing the client to use their local cache for
10 minutes - eliminating server requests and yielding instant response times. Then after 10 minutes
the 304 NotModified Response Status and Empty Body improves latency and saves the Server CPU and
bandwidth resources it didn't have to use for serializing and writing the executed Services response it
would have need to do if no Caching was enabled.
Using LastModified
The alternative to using an ETag is to use the Last-Modified Caching Validator. When you're constructing
a complex response you'll want to use the most recent Last Modified Date from all sources so that you
can determine that the cache is no longer valid when any of the sources have been updated.
If you also want to customize the clients Cache-Control behavior you can use the additional HttpResult
properties, below is an example of doing both:
public object Any(GetCustomerOrders request)
{
var response = new GetCustomerOrdersResponse {
Customer = Db.SingleById<Customer>(request.Id),
Orders = Db.Select<Order>(x => x.CustomerId == request.Id),
};
var allDates = new List<DateTime>(response.Orders.Select(x => x.ModifiedDate)) {
response.Customer.ModifiedDate,
};
return new HttpResult(response)
{
LastModified = allDates.OrderByDescending(x => x).First(),
MaxAge = TimeSpan.FromSeconds(60),
CacheControl = CacheControl.Public | CacheControl.MustRevalidate,
};
}
Which returns the Last Modified Date of the Customer record or any of their Orders as well as the
customized Cache-Control Header which together returns Response Headers similar to:
Last-Modified: Fri, 19 April 2016 05:00:00 GMT
Cache-Control: max-age=60, public, must-revalidate
Then after 60 seconds have elapsed the client will re-issue a request but instead of sending a
If-None-Match Request Header and ETag, instead sends If-Modified-Since and the Last-Modified date:
If-Modified-Since: Fri, 19 April 2016 05:00:00 GMT
The resulting behavior is identical to that of the ETag above but instead compares the LastModified dates instead of ETag strings for validity.
Short-circuiting HTTP Cache Validation
A further optimization that can be added to the HTTP Cache workflow is using IRequest.HasValidCache()
to short-circuit the execution of a Service after you've processed enough information to determine either
the ETag or LastModified for the response.
For example if you had a Service that transcodes video on-the-fly, you can use Request.HasValidCache() to
check whether the client already has the latest version of the video, if it does we can return a
304 NotModified result directly, short-circuiting the Service and saving any resources in executing the
remainder of the implementation, which in this case would bypass reading and transcoding the .mp4 video:
public object Any(GetOggVideo request)
{
var mp4Video = VirtualFileSources.GetFile($"/videos/{request.Id}.mp4");
if (mp4Video == null)
throw HttpError.NotFound($"Video #{request.Id} does not exist");
if (Request.HasValidCache(mp4Video.LastModified))
return HttpResult.NotModified();
var encodedOggBytes = EncodeToOggVideo(file.ReadAllBytes());
return new HttpResult(encodedOggBytes, "video/ogg")
{
LastModified = mp4Video.LastModified,
MaxAge = TimeSpan.FromDays(1),
};
}
New [CacheResponse] Attribute
We've briefly had a look at the existing ToOptimizedResult* API's to create Server Caches in
ServiceStack as well as using a customized HttpResult to take advantage of HTTP Caching Client features.
To make it even easier to use both, we've combined them together in a new declarative [CacheResponse]
Request Filter attribute
which as it's non-invasive and simple to add, we expect it to be the most popular option for adding caching
to your Services in future.
As a normal Request Filter Attribute it can be added at the top-level of your Service class in which case it will cache the response of All Service implementations for 60 seconds, e.g:
[CacheResponse(Duration = 60)]
public class CachedServices : Service
{
public object Any(GetCustomer request) { ... }
public object Any(GetCustomerOrders request) { ... }
}
It can also be applied individually on a single Service implementation:
[CacheResponse(Duration = 60)]
public object Any(GetCustomer request)
{
return Db.SingleById<Customer>(request.Id);
}
Or on Request DTO's, as we saw earlier on the QueryRockstarAlbums AutoQuery DynamoDB Request DTO:
[CacheResponse(Duration = 60)]
public class QueryRockstarAlbums : QueryData<RockstarAlbum> { ... }
However adding Request Filter Attributes on Request DTO's goes against our recommendation for keeping your DTO's in a separate implementation and dependency-free ServiceModel.dll as it would require a dependency on the non-PCL ServiceStack.dll which would prohibit being able to reuse your existing DTO .dll in PCL libraries, limiting their potential re-use.
You can still take advantage of the [CacheResponse] attribute on AutoQuery Services by defining
a custom implementation, at which point adding the [CacheResponse] attribute behaves as normal and
applies caching to your Service implementations. E.g. you can enable caching for multiple AutoQuery
Services with:
[CacheResponse(Duration = 60)]
public class MyCachedAutoQueryServices : Service
{
public IAutoQueryData AutoQuery { get; set; }
public object Any(QueryRockstars query) =>
AutoQuery.Execute(query, AutoQuery.CreateQuery(query, Request));
public object Any(QueryRockstarAlbums query) =>
AutoQuery.Execute(query, AutoQuery.CreateQuery(query, Request));
}
Server Cached and HTTP Caching enabled responses
When only specifying a Duration=60 ServiceStack only caches the Server Response so it behaves similar
to using the existing ToOptimizedResult() API, e.g:
public object Any(GetCustomer request)
{
return Request.ToOptimizedResultUsingCache(Cache,
Request.RawUrl, TimeSpan.FromSeconds(60),
() => Db.SingleById<Customer>(request.Id));
}
To also enable HTTP Caching features you'll need to opt-in by specifying an additional HTTP Caching directive.
E.g. including a MaxAge instructs ServiceStack to apply HTTP Caching logic and return the appropriate headers:
[CacheResponse(Duration=60, MaxAge=30)]
public object Any(GetCustomer request) => Db.SingleById<Customer>(request.Id);
Where subsequent identical requests from a cache-aware client will return their locally cached version within the first 30 seconds, between 30-60 seconds the client will re-validate the request with the Server who will return a 304 NotModified Response with an Empty Body, after 60 seconds the cache expires and the next request will re-execute the Service and populate the cache with a new response.
CacheResponse Properties
The Caching behavior of the [CacheResponse] attribute can be further customized using any of the
additional properties below:
int Duration // Cache expiry in seconds
int MaxAge // MaxAge in seconds
CacheControl CacheControl // Customize Cache-Control HTTP Headers
bool VaryByUser // Vary cache per user
string[] VaryByRoles // Vary cache for users in these roles
bool LocalCache // Use In Memory HostContext.LocalCache or HostContext.Cache
Using any of the other HTTP Cache properties will also trigger the HTTP Caching features.
When a MaxAge isn't specified, i.e:
[CacheResponse(Duration = 10, VaryByUser = true)]
public object Any(GetUserActivity request) { ... }
ServiceStack falls back to use the HttpCacheFeature.DefaultMaxAge which defaults to 10 minutes,
in addition to the VaryByUser flag will construct a unique cache key for each user and return an additional
Vary: Cookie HTTP Response Header.
Advanced CacheInfo Customization
One limitation of using a .NET Attribute to specify caching behavior is that we're limited to using
.NET constant primitives prohibiting the use of allowing custom lambda's to capture custom behavior.
This is also the reason why we need to use int for Duration and MaxAge instead of a more appropriate
TimeSpan.
But we can still intercept the way the [CacheResponse] attribute works behind-the-scenes and programmatically
enhance it with custom logic.
CacheResponseAttribute
is just a wrapper around initializing a populated
CacheInfo POCO
that it drops into the IRequest.Items dictionary where it's visible to your Service and any remaining Filters
in ServiceStack's Request Pipeline.
Essentially it's just doing this:
req.Items[Keywords.CacheInfo] = new CacheInfo { ... };
The actual validation logic for processing the CacheInfo is encapsulated within the HttpCacheFeature
Response Filter. This gives our Service a chance to modify it's behavior, e.g. in order to generically
handle all Service responses the [CacheResponse] attribute uses the IRequest.RawUrl
(the URL minus the domain) for the base CacheKey. Whilst using a RawUrl is suitable in uniquely identifying
most requests, if QueryString params were sent in a different case or in a different order it would generate
a different url and multiple caches for essentially the same request. We can remedy this behavior by changing
the base CacheKey used which is just a matter retrieving the populated the CacheInfo and change the
KeyBase to use the predictable Reverse Routing
ToGetUrl() API instead, e.g:
[CacheResponse(Duration = 60)]
public object Get(MyRequest request)
{
var cacheInfo = (CacheInfo)base.Request.GetItem(Keywords.CacheInfo);
cacheInfo.KeyBase = request.ToGetUrl(); //custom cache key
if (Request.HandleValidCache(cacheInfo))
return null;
...
return response;
}
HandleValidCache() is used to re-validate the client's request with the new Cache Key and if it's determined
the Client has a valid cache, will short-circuit the Service and return a 304 NotModified Response.
Cache-Aware Service Clients
We've now covered most of the Server Caching and HTTP Caching features in ServiceStack whose usage will automatically benefit Websites as browsers have excellent support for HTTP Caching. But .NET Desktop Apps or Xamarin.iOS and Xamarin.Android mobile clients wont see any of these benefits since none of the existing Service Clients have support for HTTP Caching.
To complete the story we've also developed a cache-aware CachedServiceClient that can be used to enhance
all existing HttpWebRequest based Service Clients which manages its own local cache as instructed by the
HTTP Caching directives, whilst the CachedHttpClient does the same for the HttpClient-based JsonHttpClient.
Both Cache-Aware clients implement the full IServiceClient interface so they should be an easy drop-in enhancement for existing applications:
IServiceClient client = new JsonServiceClient(baseUrl).WithCache();
//equivalent to:
IServiceClient client = new CachedServiceClient(new JsonServiceClient(baseUrl));
Likewise for JsonHttpClient:
IServiceClient client = new JsonHttpClient(baseUrl).WithCache();
//equivalent to:
IServiceClient client = new CachedHttpClient(new JsonHttpClient(baseUrl));
As seen above they're essentially decorators over existing .NET Service Clients where they'll append the appropriate HTTP Request Headers and inspect the HTTP Responses of GET Requests that contain HTTP Caching directives. All other HTTP Methods are just delegated through to the underlying Service Client.
The Service Clients maintain cached responses in an internal dictionary which can also be injected and shared if your app uses multiple Service Clients. For example they could use the fast binary MsgPack client for performance-sensitive queries or Services returning binary data and use a JSON client for everything else:
var sharedCache = new ConcurrentDictionary<string, HttpCacheEntry>();
IServiceClient msgPackClient = new MsgPackServiceClient(baseUrl).WithCache(sharedCache);
IServiceClient jsonClient = new JsonHttpClient(baseUrl).WithCache(sharedCache);
Improved Performance and Reliability
When caching is enabled on Services, the Cache-aware Service Clients can dramatically improve performance by eliminating server requests entirely as well as reducing bandwidth for re-validated requests. They also offer an additional layer of resiliency as re-validated requests that result in Errors will transparently fallback to using pre-existing locally cached responses. For bandwidth-constrained environments like Mobile Apps they can dramatically improve the User Experience and as they're available in all supported PCL client platforms - we recommend their use where HTTP Caching is enabled on the Server.
Community Resources on Caching
The new Caching support was developed in collaboration with members of the ServiceStack Community particularly @JezzSantos who was also developing his own ServiceStack Caching Solution in parallel which he recently wrote about in comprehensive detail - a must read if you want to learn more about HTTP Caching and explore alternative solutions for maintaining dependent caches within ServiceStack.
Service Gateway
Another valuable capability added in this release that despite being trivial to implement on top of ServiceStack's existing message-based architecture, opens up exciting new possibilities for development of loosely-coupled Modularized Service Architectures.
The new IServiceGateway interfaces represent the minimal surface area required to support ServiceStack's different calling conventions in a formalized API that supports both Sync and Async Service Integrations:
public interface IServiceGateway
{
// Normal Request/Reply Services
TResponse Send<TResponse>(object requestDto);
// Auto Batched Request/Reply Requests
List<TResponse> SendAll<TResponse>(IEnumerable<object> requestDtos);
// OneWay Service
void Publish(object requestDto);
// Auto Batched OneWay Requests
void PublishAll(IEnumerable<object> requestDtos);
}
// Equivalent Async API's
public interface IServiceGatewayAsync
{
Task<TResponse> SendAsync<TResponse>(object requestDto,
CancellationToken token = default(CancellationToken));
Task<List<TResponse>> SendAllAsync<TResponse>(IEnumerable<object> requestDtos,
CancellationToken token = default(CancellationToken));
Task PublishAsync(object requestDto,
CancellationToken token = default(CancellationToken));
Task PublishAllAsync(IEnumerable<object> requestDtos,
CancellationToken token = default(CancellationToken));
}
The minimum set of API's above requires the least burden for IServiceGateway implementers whilst the
ServiceGatewayExtensions
overlays convenience API's common to all implementations providing the nicest API's possible for Request DTO's
implementing the recommended IReturn<T> and IReturnVoid interface markers. The extension methods also
provide fallback pseudo-async support for IServiceGateway implementations that also don't implement the
optional IServiceGatewayAsync, but will use native async implementations for those that do.
Naked Request DTO's without annotations are sent as a POST but alternative Verbs are also supported
by annotating Request DTO's with
HTTP Verb Interface Markers
where Request DTO's containing IGet, IPut, etc. are sent using the typed Verb API, e.g:
[Route("/customers/{Id}")]
public class GetCustomer : IReturn<Customer>, IGet
{
public int Id { get; set ;}
}
var customer = client.Send(new GetCustomer { Id = 1 }); //GET /customers/1
//Equivalent to:
var customer = client.Get(new GetCustomer { Id = 1 });
Service Integration API's
To execute existing ServiceStack Services internally you can call ExecuteRequest(requestDto) which
passes the Request DTO along with the current IRequest into the ServiceController.Execute() to execute.
The alternative is to call ResolveService<T> to resolve an autowired instance of the Service that's
injected with the current IRequest context letting you call methods on the Service instance directly.
Below is an example of using both API's:
public object Any(GetCustomerOrders request)
{
using (var orderService = base.ResolveService<OrderService>())
{
return new GetCustomerOrders {
Customer = (Customer)base.ExecuteRequest(new GetCustomer { Id = request.Id }),
Orders = orderService.Any(new QueryOrders { CustomerId = request.Id })
};
}
}
The recommended approach now is to instead use the IServiceGateway accessible from base.Gateway
available in all Service, Razor Views, MVC ServiceStackController classes, etc. It works similar to
the ExecuteRequest() API (which it now replaces) where you can invoke a Service with just a populated
Request DTO, but instead yields an ideal typed API for Request DTO's implementing the recommended IReturn<T>
or IReturnVoid markers:
public object Any(GetCustomerOrders request)
{
return new GetCustomerOrders {
Customer = Gateway.Send(new GetCustomer { Id = request.Id }),
Orders = Gateway.Send(new QueryOrders { CustomerId = request.Id })
};
}
Or you can use the Async API if you prefer the non-blocking version:
public async Task<GetCustomerOrdersResponse> Any(GetCustomerOrders request)
{
return new GetCustomerOrdersResponse {
Customer = await Gateway.SendAsync(new GetCustomer { Id = request.Id }),
Orders = await Gateway.SendAsync(new QueryOrders { CustomerId = request.Id })
};
}
The capability that sets the ServiceGateway apart (other than offering a nicer API to work with) is that this System could later have its Customer and Order Subsystems split out into different hosts and this exact Service implementation would continue to function as before, albeit a little slower due to the overhead of any introduced out-of-process communications.
The default implementation of IServiceGateway uses the
InProcessServiceGateway
which delegates the Request DTO to the appropriate ServiceController.Execute() or
ServiceController.ExecuteAsync() methods to execute the Service. One noticeable difference is that any
Exceptions thrown by downstream Services are automatically converted into the same WebServiceException
that clients would throw when calling the Service externally, this is so Exceptions are indistinguishable
whether it's calling an internal Service or an external one, which begins touching on the benefits of the
Gateway...
The ServiceGateway is the same interface whether you're calling an Internal Service on the Server or a remote Service from a client. It exposes an ideal message-based API that's optimal for remote Service Integrations that also supports Auto Batched Requests for combining multiple Service Calls into a single Request, minimizing latency when possible.
Substitutable Service Gateways
These characteristics makes it easy to substitute and customize the behavior of the Gateway as visible in the
examples below. The easiest scenario to support is to redirect all Service Gateway calls to a remote
ServiceStack instance which can be done by registering any .NET Service Client against the IServiceGateway
interface, e.g:
public override void Configure(Container container)
{
container.Register<IServiceGateway>(c => new JsonServiceClient(baseUrl));
}
A more likely scenario you'd want to support is a mix where internal requests are executed in-process and external requests call their respective Service. If your system is split in two this becomes a simple check to return the local InProcess Gateway for Requests which are defined in this ServiceStack instance otherwise return a Service Client configured to the alternative host when not, e.g:
public class CustomServiceGatewayFactory : ServiceGatewayFactoryBase
{
public override IServiceGateway GetGateway(Type requestType)
{
var isLocal = HostContext.Metadata.RequestTypes.Contains(requestType);
var gateway = isLocal
? (IServiceGateway)base.localGateway
: new JsonServiceClient(alternativeBaseUrl);
return gateway;
}
}
For this we needed to implement the
IServiceGatewayFactory
so we can first capture the current IRequest that's needed in order to call the In Process Service Gateway with.
The convenience ServiceGatewayFactoryBase
abstracts the rest of the API away so you're only tasked with returning the appropriate Service Gateway for
the specified Request DTO.
Capturing the current IRequest makes the Gateway factory instance non-suitable to use as a singleton,
so we'll need to register it with a ReuseScope.None scope so a new instance is resolved each time:
public override void Configure(Container container)
{
container.Register<IServiceGatewayFactory>(x => new CustomServiceGatewayFactory())
.ReusedWithin(ReuseScope.None);
}
Service Discovery Gateways
We're fortunate to have a vibrant community which quickly saw the value in this new capability where they were quick to jump in and contribute their own well-documented and supported value-added OSS solutions:
ServiceStack.Discovery.Consul
The ConsulFeature plugin by Scott Mackay leverages the hardened distributed Discovery Services and highly available features in consul.io to provide automatic registration and de-registration of ServiceStack Services on AppHost StartUp and Dispose that's available from:
PM> Install-Package ServiceStack.Discovery.Consul
Without any additional effort beyond registering the ConsulFeature plugin and starting a new ServiceStack
Instance it provides an auto-updating, self-maintaining and periodically checked registry of available Services:
public override void Configure(Container container)
{
SetConfig(new HostConfig {
WebHostUrl = "http://api.acme.com:1234", // Externally resolvable BaseUrl
});
Plugins.Add(new ConsulFeature()); // Register the plugin, that's it!
}
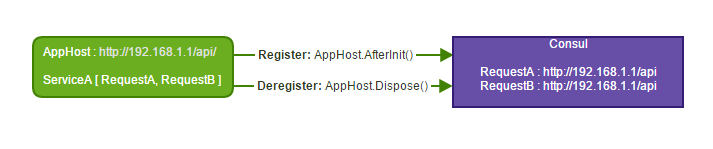
Once registered, the Service Gateway works as you'd expect where internal requests are executed in process and external requests queries the Consul registry to discover the appropriate and available Service to call:
public class MyService : Service
{
public void Any(RequestDTO dto)
{
// Gateway will automatically route external requests to correct service
var internalCall = Gateway.Send(new InternalDTO { ... });
var externalCall = Gateway.Send(new ExternalDTO { ... });
}
}
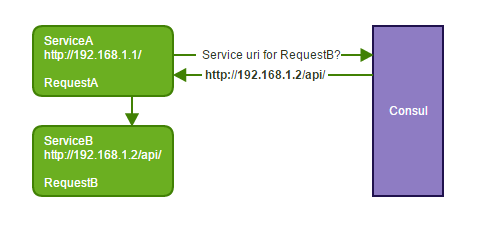
ServiceStack.Discovery.Redis
The RedisServiceDiscoveryFeature by Richard Safier has similar goals to provide transparent service discovery but only requires access to Redis-backed datastore, but is otherwise just as easy to install:
PM> Install-Package ServiceStack.Discovery.Redis
and Configure:
public override void Configure(Container container)
{
container.Register<IRedisClientsManager>(c => new RedisManagerPool(...));
SetConfig(new HostConfig {
WebHostUrl = "http://api.acme.com:1234"
});
Plugins.Add(new RedisServiceDiscoveryFeature());
}
Once registered, calling the same Gateway API's function the same way with internal requests executed internally and external requests sent to the appropriate available node:
public class MyService : Service
{
public void Any(RequestDTO dto)
{
var internalCall = Gateway.Send(new InternalDTO { ... });
var externalCall = Gateway.Send(new ExternalDTO { ... });
try
{
var unknown = Gateway.Send(new ExternalDTOWithNoActiveNodesOnline());
}
catch(RedisServiceDiscoveryGatewayException e)
{
// If a DTO type is not local or resolvable by Redis discovery process
// a RedisServiceDiscoveryGatewayException will be thrown
}
}
}
Since all Redis Discovery data is stored in a redis instance the state of all available nodes can be viewed with any Redis GUI:
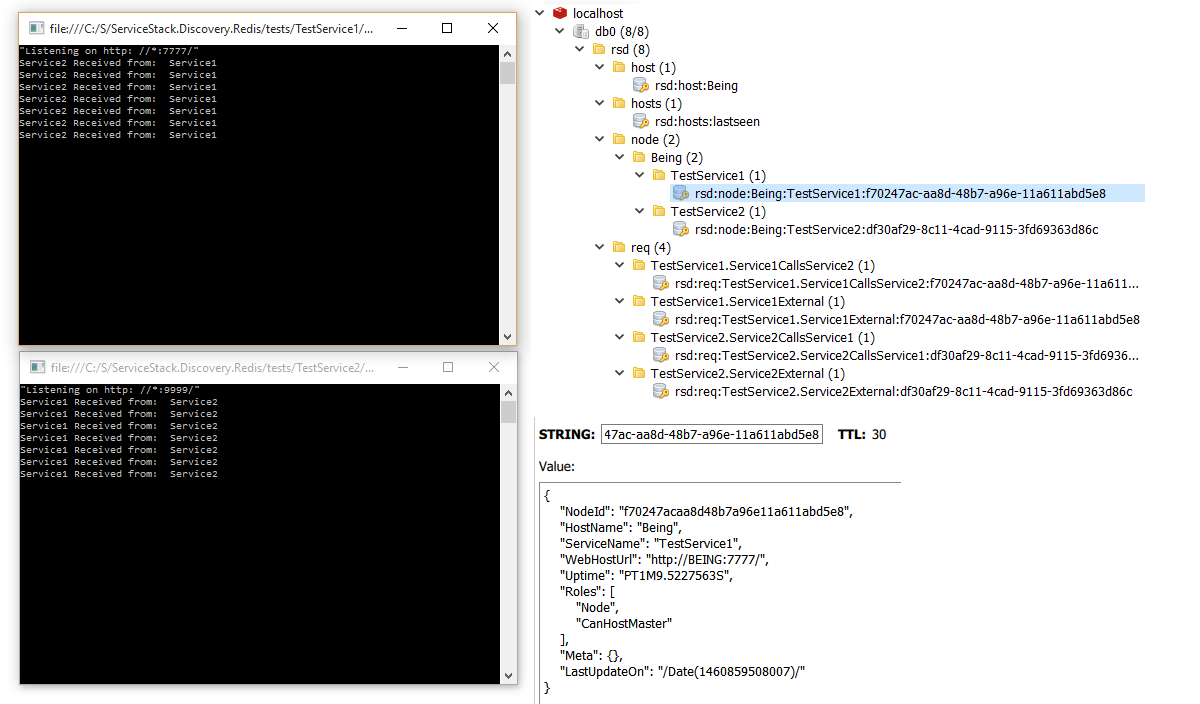
ServiceStack.SimpleCloudControl
In addition to this Redis Discovery Service Richard is also developing a series of ServiceStack plugins that enhances the functionality of ServiceStack.Discovery.Redis and provides cluster awareness to additional aspects of a ServiceStack AppHost's internal state.
Designing for Microservices
Whether or not Systems benefit overall from a fine-grained microservices architecture, enough to justify the additional latency, management and infrastructure overhead it requires, we still see value in the development process of designing for Microservices where decoupling naturally isolated components into loosely-coupled subsystems has software-architecture benefits with overall complexity of an entire system being reduced into smaller, more manageable logical scopes which encapsulates their capabilities behind small, re-usable, well-defined facades.
The ServiceGateway and its Services Discovery ecosystem together with ServiceStack's recommended use of impl-free reusable POCO DTO's and its ability to modularize Service implementations across multiple projects naturally promote a microservices-ready architecture where Service interactions are loosely-coupled behind well-defined, reusable, coarse-grained messages. Designing systems in this way later allows the isolated Service Implementation .dll to be extracted from the main System and wrapped into its own AppHost. Together with an agreed Service Discovery solution, allows you to spawn multiple instances of the new Service - letting you scale, deploy and maintain it independently from the rest of the system.
CSV Deserialization Support
The introduction of the new AutoQuery Data feature and it's MemorySource suddenly made full CSV support
a lot more appealing which caused CSV Deserialization support to be bumped up high on the priority list
where it's implementation is now complete. This now unlocks the ability to create fully-queryable Services
over flat-file .csv's (or Excel spreadsheets exported to .csv) by just deserializing CSV into a List of
POCO's and registering it with AutoQuery Data:
var pocos = File.ReadAllText("path/to/data.csv").FromCsv<List<Poco>>();
//AutoQuery Data Plugin
Plugins.Add(new AutoQueryDataFeature()
.AddDataSource(ctx => ctx.MemorySource(pocos)));
// AutoQuery DTO
[Route("/pocos")]
public class QueryPocos : QueryData<Poco> {}
Super CSV Format
A noteworthy feature that sets ServiceStack's CSV support apart is that it's built on the compact and very fast
JSV format which not only can
deserialize a tabular flat file of scalar values at high-speed, it also supports deeply nested object graphs
which are encoded in JSV and escaped in a CSV field as normal. An example of this can be seen in a HTTP
sample log fragment below where the HTTP Request Headers are a serialized from a Dictionary<string,string>:
Id,HttpMethod,AbsoluteUri,Headers
1,GET,http://localhost:55799,"{Connection:keep-alive,Accept:""text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8"",Accept-Encoding:""gzip, deflate, sdch"",Accept-Language:""en-US,en;q=0.8"",Host:""localhost:55799"",User-Agent:""Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.112 Safari/537.36"",Upgrade-Insecure-Requests:1}"
Being such a versatile file format opens up a lot of new possibilities, e.g. instead of capturing seed data in code you could maintain them in plain-text .csv files and effortlessly load them on App Startup, e.g:
using (var db = container.Resolve<IDbConnectionFactory>().Open())
{
if (db.CreateTableIfNotExists<Country>()) //returns true if Table created
{
List<Country> countries = "~/App_Data/countries.csv".MapHostAbsolutePath()
.ReadAllText().FromCsv<List<Country>>();
db.InsertAll(countries);
}
}
All Services now accept CSV Content-Types
Another immediate benefit of CSV Deserialization is that now all Services can now process the CSV Content-Type.
Being a tabular data format, CSV shines when it's processing a list of DTO's, one way to do that in
ServiceStack is to have your Request DTO inherit List<T>:
[Route("/pocos")]
public class Pocos : List<Poco>, IReturn<Pocos>
{
public Pocos() {}
public Pocos(IEnumerable<Poco> collection) : base(collection) {}
}
It also behaves the same way as CSV Serialization but in reverse where if your Request DTO is annotated
with either [DataContract] or the more explicit [Csv(CsvBehavior.FirstEnumerable)] it will automatically
deserialize the CSV into the first IEnumerable property, so these 2 Request DTO's are equivalent to above:
[Route("/pocos")]
[DataContract]
public class Pocos : IReturn<Pocos>
{
[DataMember]
public List<Poco> Items { get; set; }
}
[Route("/pocos")]
[Csv(CsvBehavior.FirstEnumerable)]
public class Pocos : IReturn<Pocos>
{
public List<Poco> Items { get; set; }
}
In addition to the above flexible options for defining CSV-friendly Services, there's also a few different
options for sending CSV Requests to the above Services. You can use the new CSV PostCsvToUrl() extension
methods added to HTTP Utils:
string csvText = File.ReadAllText("pocos.csv");
//Send CSV Text
List<Poco> response = "http://example.org/pocos"
.PostCsvToUrl(csvText)
.FromCsv<List<Poco>>();
//Send POCO DTO's
List<Poco> dtos = csvText.FromCsv<List<Poco>>();
List<Poco> response = "http://example.org/pocos"
.PostCsvToUrl(dtos)
.FromCsv<List<Poco>>();
Alternatively you can use the CsvServiceClient which has the nice Typed API's you'd expect from a
Service Client:
var client = new CsvServiceClient(baseUrl);
Pocos response = client.Post(new Pocos(dtos));
Ideal for Auto Batched Requests
The CsvServiceClient by virtue of being configured to use a well-defined Tabular data format is perfect
for sending
Auto-Batched Requests
which by definition send a batch of POCO's making the CSV format the most compact text format to send them with:
var requests = new[]
{
new Request { ... },
new Request { ... },
new Request { ... },
};
var responses = client.SendAll(requests);
CSV Request Logger
Flipping the switch on CSV Deserialization has opened up the potential for a lot more useful features. One of the areas we thought to be particularly valuable is being able to store daily Request Logs in a plain-text structured format, that way they could be immediately inspectable with a text editor or for even better inspection, opened in a spreadsheet and benefit from its filterable, movable, resizable and sortable columns.
To enable CSV Request Logging you just need to register the RequestLogsFeature and configure it to use the
CsvRequestLogger:
Plugins.Add(new RequestLogsFeature {
RequestLogger = new CsvRequestLogger(),
});
This will register the CSV Request logger with the following overridable defaults:
Plugins.Add(new RequestLogsFeature {
RequestLogger = new CsvRequestLogger(
files = new FileSystemVirtualPathProvider(this, Config.WebHostPhysicalPath),
requestLogsPattern = "requestlogs/{year}-{month}/{year}-{month}-{day}.csv",
errorLogsPattern = "requestlogs/{year}-{month}/{year}-{month}-{day}-errors.csv"
appendEvery = TimeSpan.FromSeconds(1)
),
});
Where Request Logs are flushed every 1 second using a background Timer to a daily log maintained in
the logical date format structure above. As it would be useful to be able to inspect any errors in isolation,
errors are also written to a separate YYYY-MM-DD-errors.csv format, in addition to the main Request logs.
Virtual FileSystem
To efficiently support Appending to existing files as needed by the CsvRequestLogger we've added new
AppendFile API's and implementations for Memory and FileSystem Virtual File Providers:
interface IVirtualFiles
{
void AppendFile(string filePath, string textContents);
void AppendFile(string filePath, Stream stream);
}
OrmLite
Updating existing values
The new UpdateAdd API's contributed by Luis Madaleno provides several
Typed API's for updating existing values:
//Increase everyone's Score by 3 points
db.UpdateAdd(new Person { Score = 3 }, fields: x => x.Score);
//Remove 5 points from Jackson Score
db.UpdateAdd(new Person { Score = -5 }, x => x.Score, x => where: x.LastName == "Jackson");
//Graduate everyone and increase everyone's Score by 2 points
var q = db.From<Person>().Update(x => new { x.Points, x.Graduated });
db.UpdateAdd(new Person { Points = 2, Graduated = true }, q);
//Add 10 points to Michael's score
var q = db.From<Person>()
.Where(x => x.FirstName == "Michael")
.Update(x => x.Points);
db.UpdateAdd(new Person { Points = 10 }, q);
Note: Any non-numeric values in an
UpdateAddstatement (e.g. strings) are replaced as normal.
BelongsTo Attribute
The [BelongTo] attribute can be used for specifying how Custom POCO results are mapped when the resultset
is ambiguous, e.g:
class A {
public int Id { get; set; }
}
class B {
public int Id { get; set; }
public int AId { get; set; }
}
class C {
public int Id { get; set; }
public int BId { get; set; }
}
class Combined {
public int Id { get; set; }
[BelongTo(typeof(B))]
public int BId { get; set; }
}
var q = db.From<A>()
.Join<B>()
.LeftJoin<B,C>();
var results = db.Select<Combined>(q); //Combined.BId = B.Id
Deprecating Legacy OrmLite API's
In order to gracefully clean up OrmLite's API Surface area and separate the modern recommended API's
from the Legacy ones we've deprecated the Legacy API's which we plan to move into a separate
ServiceStack.OrmLite.Legacy namespace. Once moved, any use of Legacy API's will require including
the additional namespace below:
using ServiceStack.OrmLite.Legacy;
The API's that have been deprecated are those with *Fmt suffix using in-line escaped string and the
old-style C# string.Format() syntax for familiarity, e.g:
var tracks = db.SelectFmt<Track>("Artist = {0} AND Album = {1}",
"Nirvana",
"Nevermind");
Instead we recommend the use of Typed APIs:
var tracks = db.Select<Track>(x => x.Artist == "Nirvana" && x.Album == "Nevermind");
Or when needed, Custom SQL API's that use @parameter names initialized with anonymous objects:
var tracks = db.Select<Track>("Artist = @artist AND Album = @album",
new { artist = "Nirvana", album = "Nevermind" });
var tracks = db.SqlList<Track>(
"SELECT * FROM Track WHERE Artist = @artist AND Album = @album",
new { artist = "Nirvana", album = "Nevermind" });
As they both execute parameterized statements behind-the-scenes.
The other set of API's that have been tagged to move out of the primary ServiceStack.OrmLite and reduce
ambiguity of the existing API surface area are those that inject an SqlExpression<T>, e.g:
var tracks = db.Select<Track>(q =>
q.Where(x => x.Artist == "Nirvana" && x.Album == "Nevermind"));
These overloaded API's would often confuse IDE intellisense which were unsure whether to provide
intelli-sense for Track or SqlExpression<Track> members. In future only POCO Data Models will be
injected so the above API's should instead be changed to create and pass in an SqlExpression<Track>
using db.From<T>, e.g:
var tracks = db.Select(db.From<Track>()
.Where(x => x.Artist == "Nirvana" && x.Album == "Nevermind"));
PocoDynamo
Support for DynamoDB's UpdateItem to modify an existing Item Attribute Value is now available.
The simplest usage is to pass in a partially populated POCO where any Hash or Range Keys are added to the Key Condition and any non-default values are replaced. E.g the query below updates the Customer's Age to 42:
db.UpdateItemNonDefaults(new Customer { Id = customer.Id, Age = 42 });
DynamoDB's UpdateItem supports 3 different operation types:
PUTto replace an Attribute ValueADDto add to an existing Attribute ValueDELETEto delete the specified Attributes
Examples of all 3 are contained in the examples below which changes the Customer's Nationality to
Australian, reduces their Age by 1 and deletes their Name and Orders:
db.UpdateItem(customer.Id,
put: () => new Customer {
Nationality = "Australian"
},
add: () => new Customer {
Age = -1
},
delete: x => new { x.Name, x.Orders });
The same Typed API above is also available in the more flexible and untyped form below:
db.UpdateItem<Customer>(new DynamoUpdateItem
{
Hash = customer.Id,
Put = new Dictionary<string, object>
{
{ "Nationality", "Australian" },
},
Add = new Dictionary<string, object>
{
{ "Age", -1 }
},
Delete = new[] { "Name", "Orders" },
});
ServiceStack.Redis
More robust Exception handling of Sentinel Errors were added and now reconnections that occur in the middle of processing a command are gracefully retried and executed.
New API's were added to remove multiple values from a Sorted Set:
interface IRedisClient {
long RemoveItemsFromSortedSet(string setId, List<string> values);
}
interface IRedisNativeClient {
long ZRem(string setId, byte[][] values);
}
ServiceStackIDEA
The ServiceStack IDEA Android Studio plugin was updated to support Android Studio 2.0.
Community
ServiceStack.EventStore
The ServiceStack community has been very active in the last month with the developers over at MacLean Electrical in addition to the Consul Discovery Plugin having also released their CQRS and event-sourced system plugin for ServiceStack using GetEventStore:
PM> Install-Package ServiceStack.EventStore
ServiceStack.SimpleCloudControl
Building on capabilities from his ServiceStack.Discovery.Redis Service Richard Safier is developing a collection of useful plugins which add enhanced introspection of the state, status and health of a cluster of ServiceStack instances. The available plugins in development include:
- SimpleCloudControlFeature
- SimpleMQControlFeature
- SimpleHybridCacheFeature
- SimpleCloudConfig
- SimpleCloudControlAdminFeature
ServiceStackWithQuartz
Michael Clark has created a Plugin that allows an easy registration of all Quartz Jobs within ServiceStack's Funq container. This allows for dependency injection within any Quartz Job. Get Started with:
PM> Install-Package ServiceStack.Funq.Quartz
Also checkout Michael's Introductory Post for more details.
Caching Anyone?
If you missed the link to Jezz Santos comprehensive post on HTTP Caching within ServiceStack from earlier, it's one to checkout when you can set aside time for a long, good read.
Other Features
- Changed
ServiceStack.Interfacesto Profile 328 adding support Windows Phone 8.1 - New
IHasStatusDescriptioncan be added on Exceptions to customize theirStatusDescription - New
IHasErrorCodecan be used to customize theErrorCodeused, instead of its Exception Type - New
AppHost.OnLogErrorcan be used to override and suppress service error logging