Ollama can be used as an AI Provider type to process LLM requests in AI Server.
Setting up Ollama
When using Ollama as an AI Provider, you will need to ensure the models you want to use are available in your Ollama instance.
This can be done via the command ollama pull <model-name> to download the model from the Ollama library.
Once the model is downloaded, and your Ollama instance is running and accessible to AI Server, you can configure Ollama as an AI Provider in AI Server Admin Portal.
Configuring Ollama in AI Server
Navigating to the Admin Portal in AI Server, select the AI Providers menu item on the left sidebar.
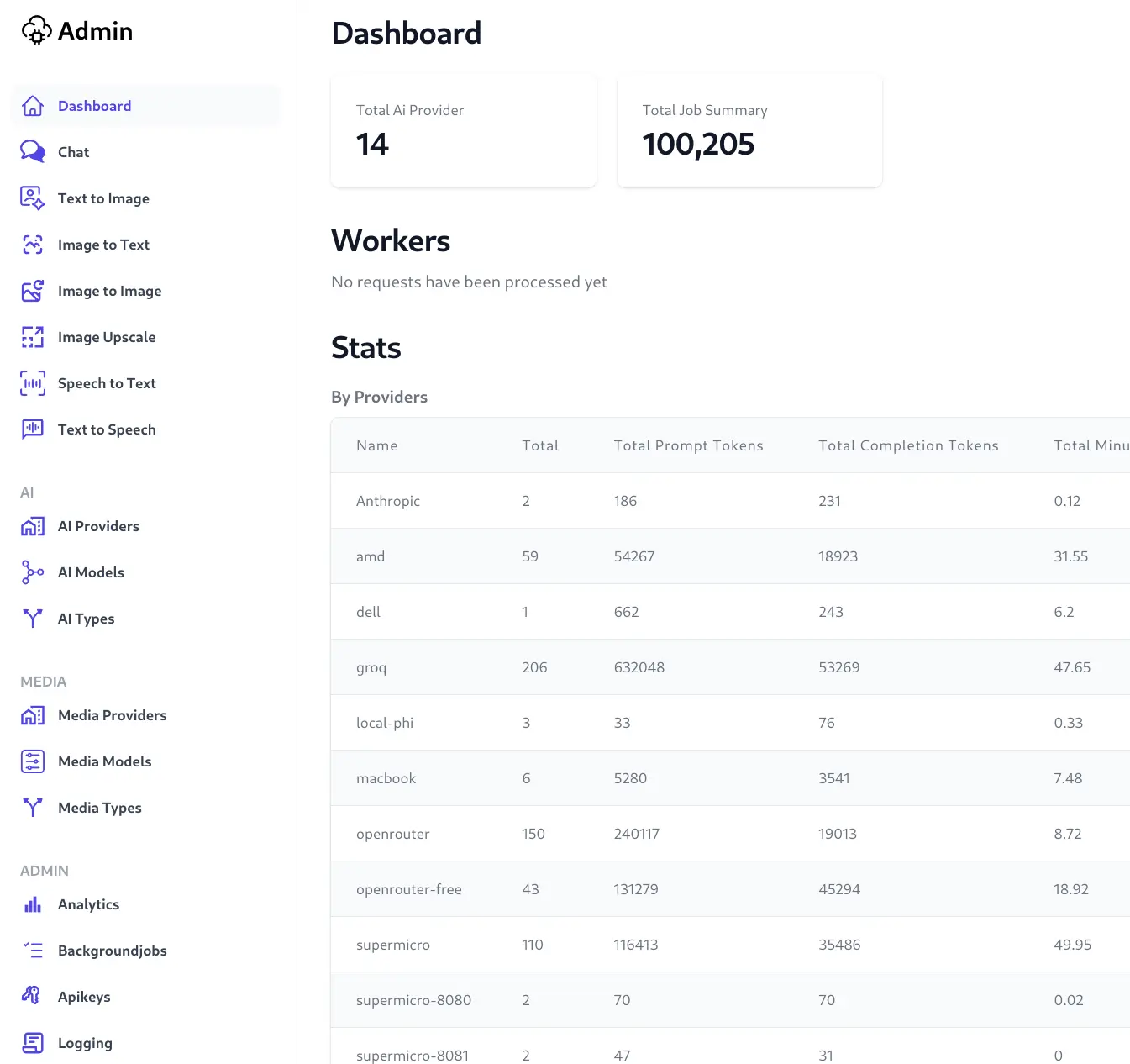
Click on the New Provider button at the top of the grid.
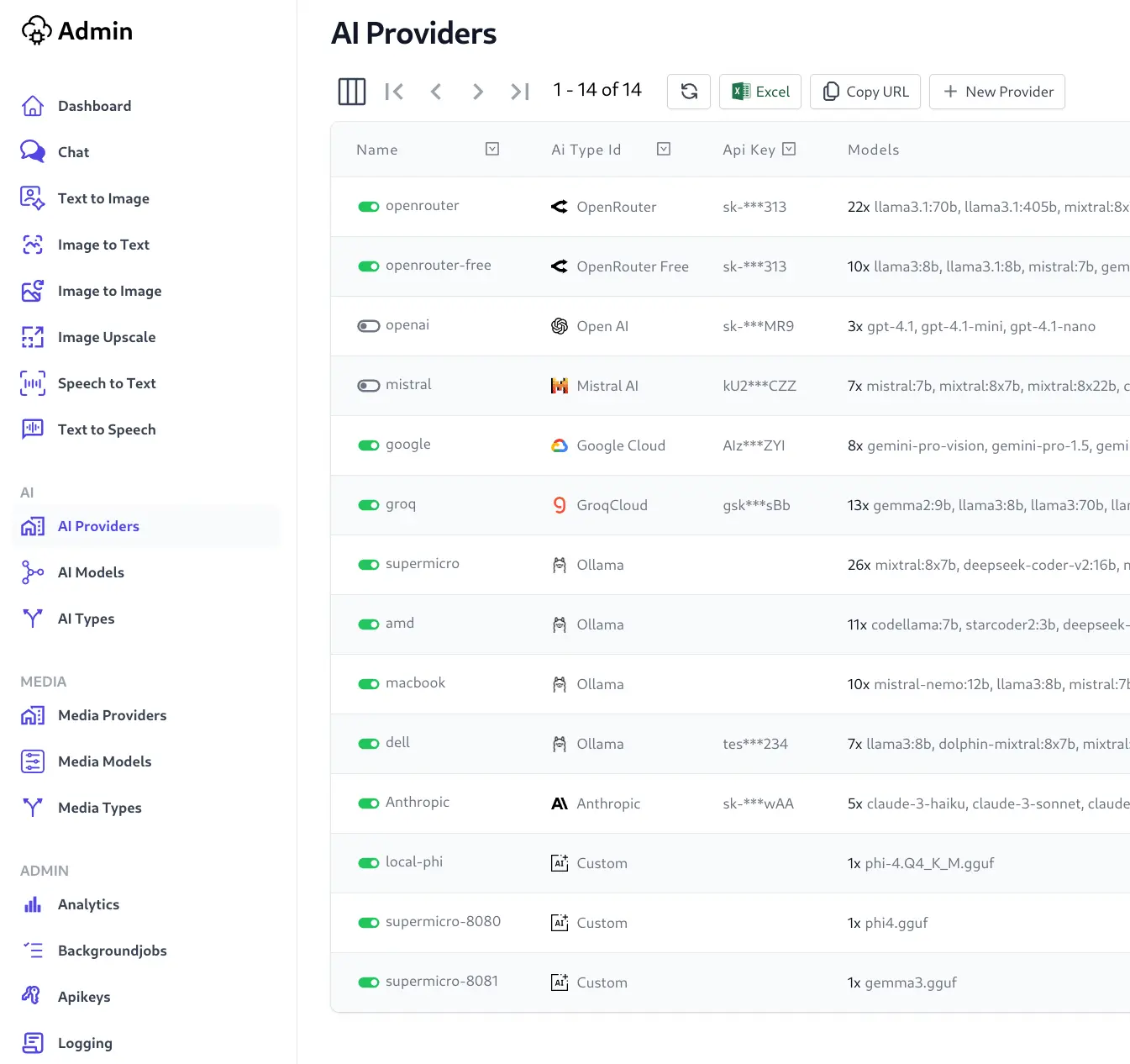
Select Ollama as the Provider Type at the top of the form, and fill in the required fields:
- Name: A friendly name for the provider.
- Endpoint: The URL of your Ollama instance, eg
http://localhost:11434. - API Key: Optional API key to authenticate with your Ollama instance.
- Priority: The priority of the provider, used to determine the order of provider selection if multiple provide the same model.
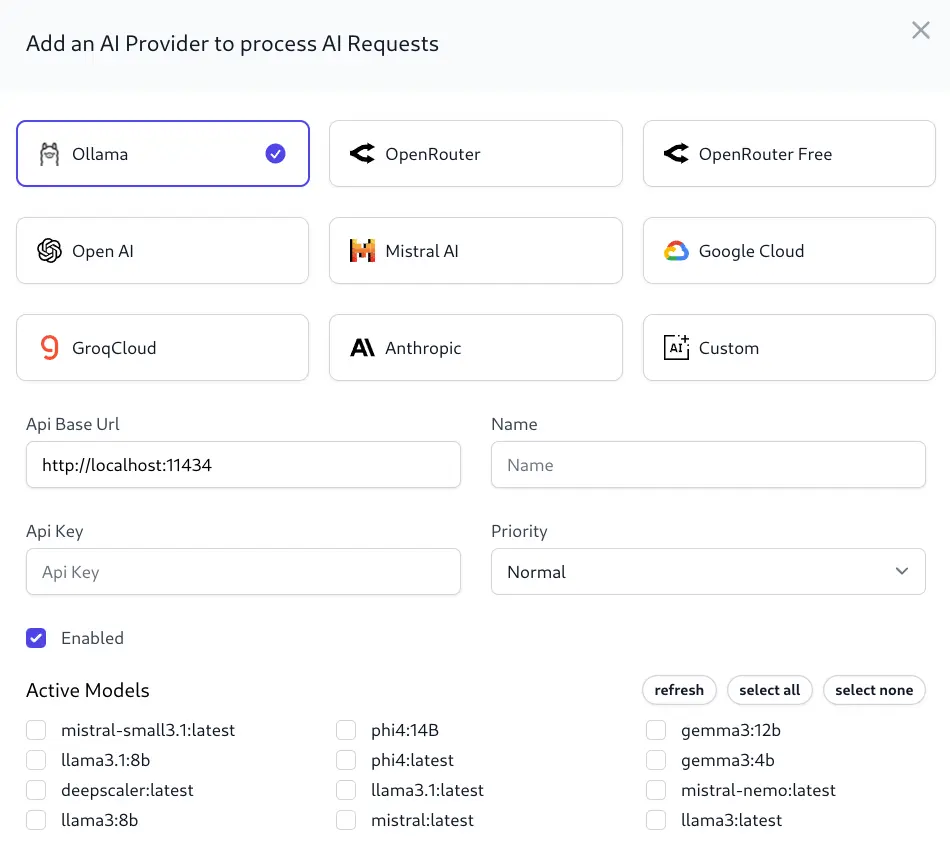
Once the URL (and optional API Key) is set, requests will be made to your Ollama instance to list available models. By default, it will look for a locally running Ollama instance on port 11434, but you can change the URL to point to your Ollama instance. These will then be displayed as options to enable for the provider you are configuring.
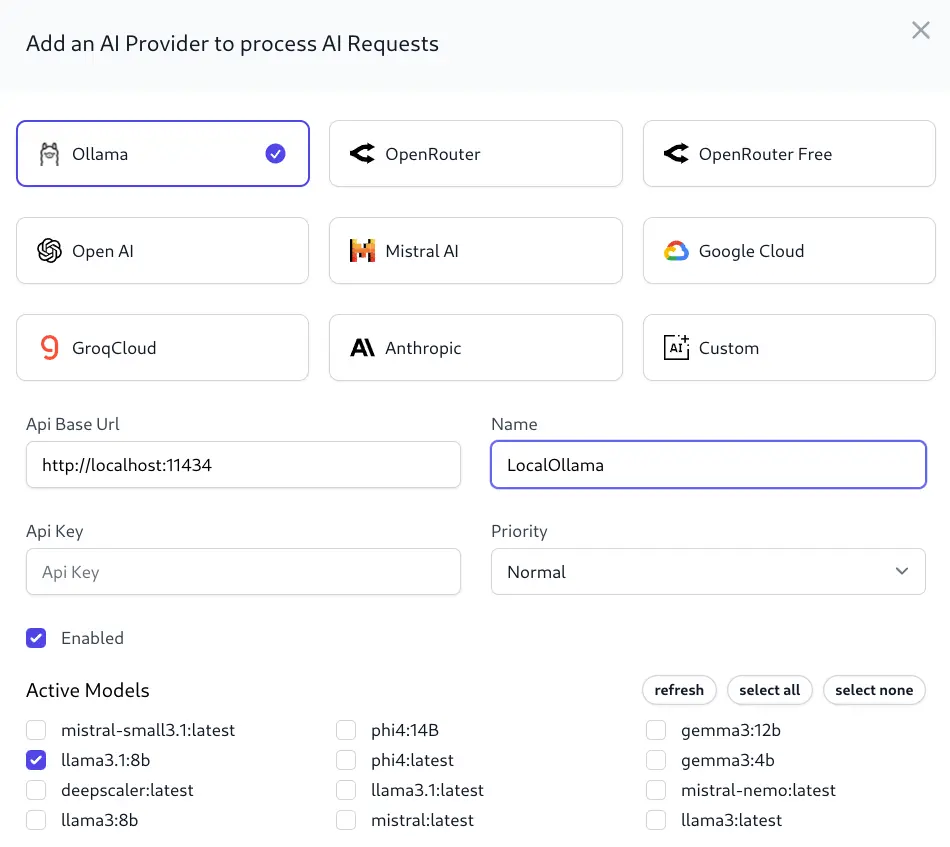
Select the models you want to enable for this provider, and click Save to save the provider configuration.
Using Ollama models in AI Server
Once configured, you can make requests to AI Server to process LLM requests using the models available in your Ollama instance.
Model names in AI Server are common across all providers, enabling you to switch or load balance between providers without changing your client code. See Usage for more information on making requests to AI Server.