AI Server provides a unified API to process requests for AI services to access LLMs, Image Generation, Transcription, and more. The API is designed to be simple to use and easy to integrate into your applications providing many supported languages and frameworks.
Chat UI
AI Server's Chat UI lets upi send Open AI Chat requests with custom system prompts to any of its active LLMs:
https://localhost:5006/Chat
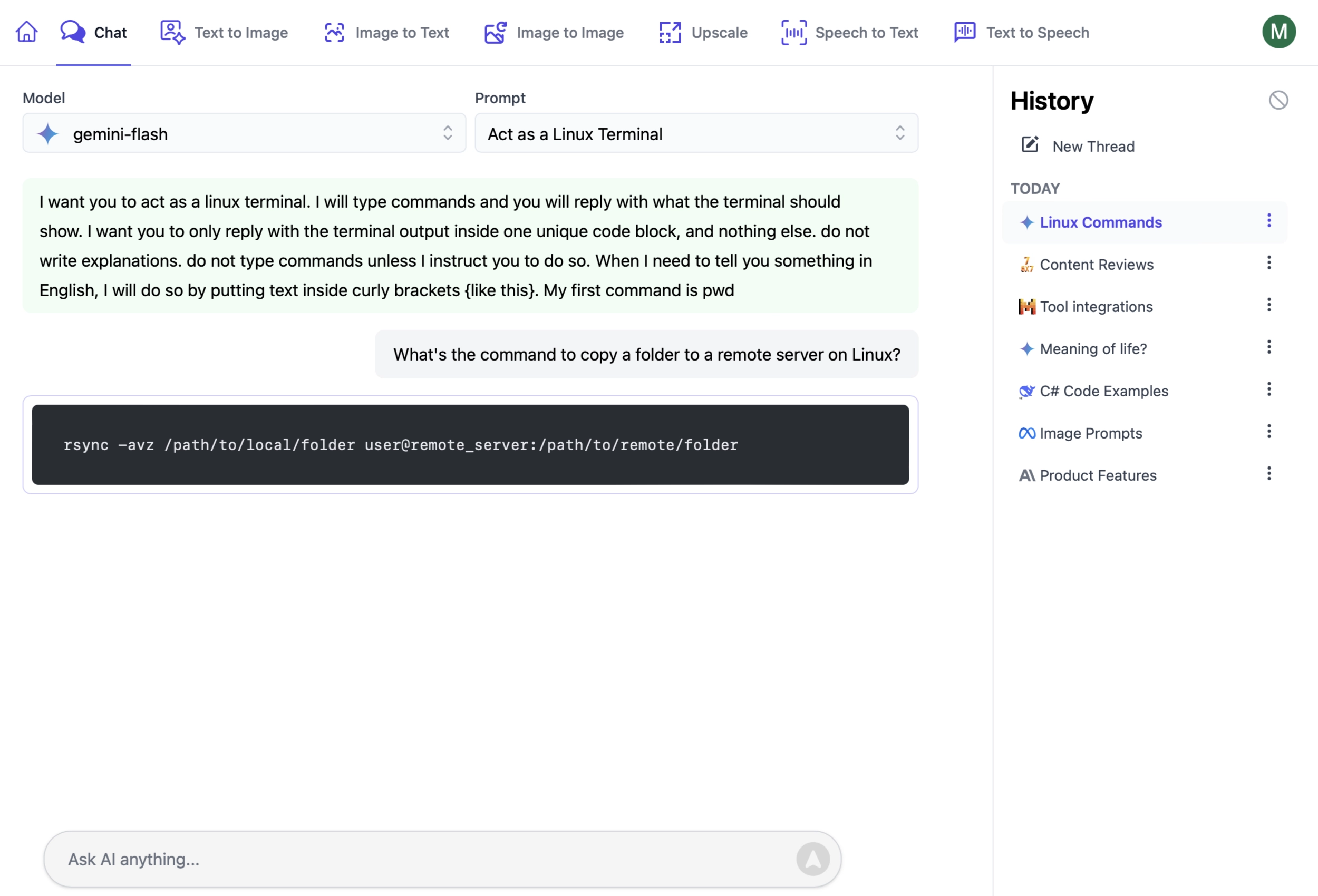
Making a Chat Request
To make a chat request to AI Server, you can use the /api/OpenAiChatCompletion endpoint. This endpoint requires a OpenAiChatCompletion request DTO that contains a property matching the OpenAI API.
Sync Open AI Chat Completion
var client = GetLocalApiClient(AiServerUrl);
var response = client.Post(new OpenAiChatCompletion {
Model = "llama3.1:8b",
Messages =
[
new() { Role = "system", Content = "You are a helpful AI assistant." },
new() { Role = "user", Content = "How do LLMs work?" }
],
MaxTokens = 50
});
var answer = response.Choices[0].Message.Content;
This request will generate a response from the llama3:8b model using the system and user messages provided. This will perform the operation synchronously, waiting for the response to be generated before returning it to the client.
Alternatively, you can call the same endpoint asynchronously by using the /api/QueueOpenAiChatCompletion endpoint. This will queue the request for processing and return a URL to check the status of the request and download the response when it's ready.
Queued Open AI Chat Completion
var client = GetLocalApiClient(AiServerUrl);
var response = client.Post(new QueueOpenAiChatCompletion
{
Request = new()
{
Model = "gpt-4-turbo",
Messages =
[
new() { Role = "system", Content = "You are a helpful AI assistant." },
new() { Role = "user", Content = "How do LLMs work?" }
],
MaxTokens = 50
},
});
// Poll for Job Completion Status
GetOpenAiChatStatusResponse status = new();
while (status.JobState is BackgroundJobState.Started or BackgroundJobState.Queued)
{
status = await client.GetAsync(new GetOpenAiChatStatus { RefId = response.RefId });
await Task.Delay(1000);
}
var answer = status.Result.Choices[0].Message.Content;
Additional optional features on the request to enhance the usage of AI Server include:
- RefId: A unique identifier for the request specified by the client to more easily track the progress of the request.
- Tag: A tag to help categorize the request for easier tracking.
RefId and Tag are available on both synchronous and asynchronous requests, where as Queue requests also support:
- ReplyTo: A URL to send a POST request to when the request is complete.
Open AI Chat with ReplyTo Callback
The Queued API also accepts a ReplyTo Web Callback for a more reliable push-based App integration where responses are posted back to a custom URL Endpoint:
var correlationId = Guid.NewGuid().ToString("N");
var response = client.Post(new QueueOpenAiChatCompletion
{
//...
ReplyTo = $"https://example.org/api/OpenAiChatResponseCallback?CorrelationId=${correlationId}"
});
Your callback can add any additional metadata on the callback to assist your App in correlating the response with
the initiating request which just needs to contain the properties of the OpenAiChatResponse you're interested in
along with any metadata added to the callback URL, e.g:
public class OpenAiChatResponseCallback : IPost, OpenAiChatResponse, IReturnVoid
{
public Guid CorrelationId { get; set; }
}
public object Post(OpenAiChatResponseCallback request)
{
// Handle OpenAiChatResponse callabck
}
Unless your callback API is restricted to only accept requests from your AI Server, you should include a
unique Id like a Guid in the callback URL that can be validated against an initiating request to ensure
the callback can't be spoofed.
Using the AI Server Request DTOs with other OpenAI compatible APIs
One advantage of using AI Server is that it provides a common set of request DTOs in 11 different languages that are compatible with OpenAI's API. This allows you to switch between OpenAI and AI Server without changing your client code. This means you can switch to using typed APIs in your preferred language with your existing service providers OpenAI compatible APIs, and optionally switch to AI Server when you're ready to self-host your AI services for better value.
var client = new JsonApiClient("https://api.openai.com");
client.BearerToken = Environment.GetEnvironmentVariable("OPENAI_API_KEY");
// Using AI Server DTOs with OpenAI API
var request = new OpenAiChatCompletion {
Model = "gpt-4-turbo",
Messages = [
new() { Role = "system", Content = "You are a helpful AI assistant." },
new() { Role = "user", Content = "What is the capital of France?" }
],
MaxTokens = 20
};
var response = await client.PostAsync<OpenAiChatResponse>(
"/v1/chat/completions",
request);
This shows usage of the OpenAiChat request DTO directly with OpenAI's API using the ServiceStack JsonApiClient, so you get the benefits of using typed APIs in your preferred language with your existing service providers OpenAI compatible APIs.