Image to Text UI
AI Server's Image to Text UI lets you request image classifications from its active Comfy UI Agents:
https://localhost:5006/ImageToText
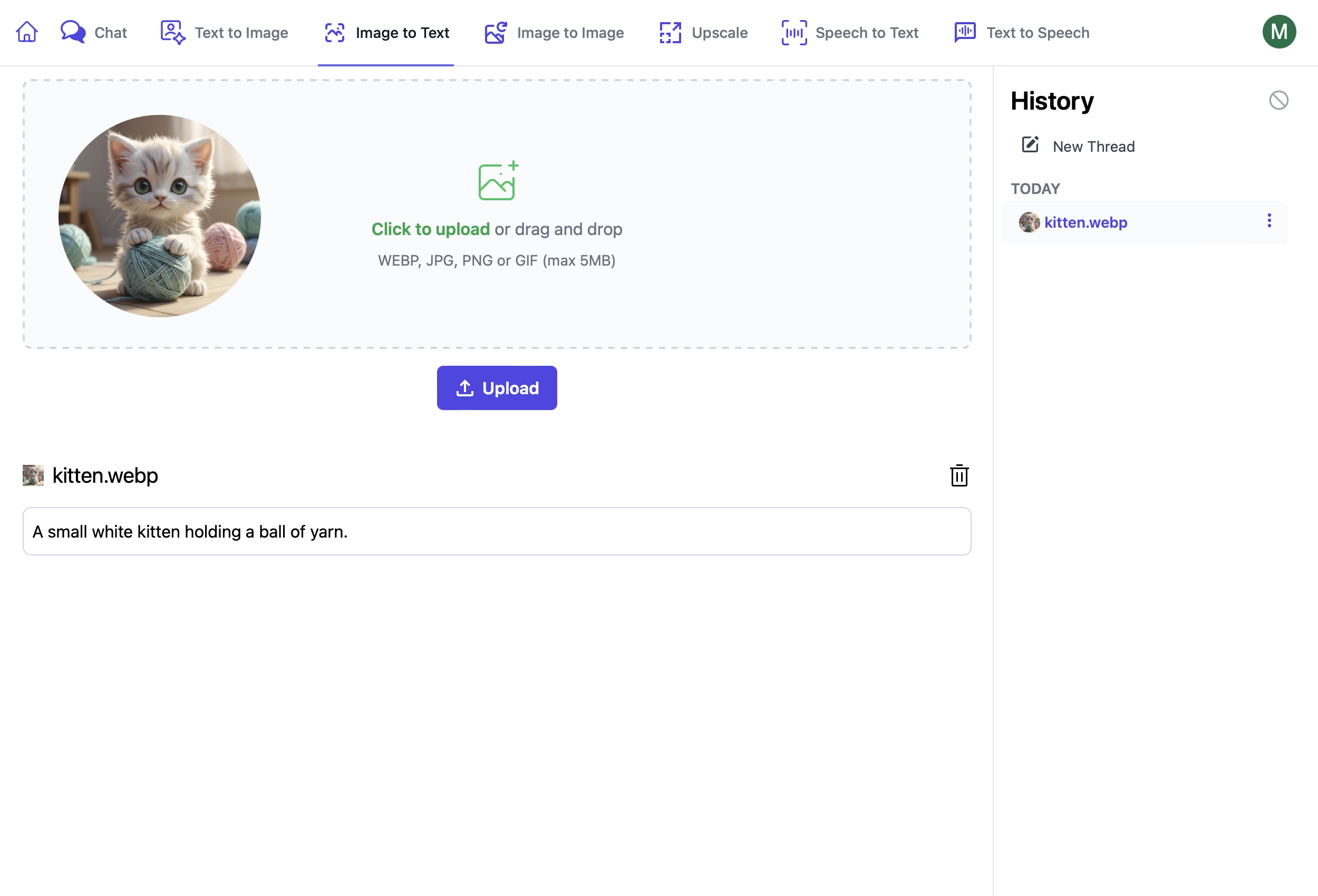
Using Image to Text Endpoints
These endpoints are used in a similar way to other AI Server endpoints where you can provide:
RefId- provide a unique identifier to track requestsTag- categorize like requests under a common group
In addition Queue requests can provide:
ReplyTo- URL to send a POST request to when the request is complete
Ollama Vision Models
If AI Server has access to any Ollama Vision Models (e.g. gemma3:27b or mistral-small), it can be used instead to get information about the uploaded image:
Model- the ollama vision model to usePrompt- vision model prompt
Image to Text
using var fsImage = File.OpenRead("files/test_image.jpg");
var response = client.PostFileWithRequest(new ImageToText(),
new UploadFile("image", fsImage, "image"));
Queue Image to Text
using var fsImage = File.OpenRead("files/test_image.jpg");
var response = client.PostFileWithRequest(new QueueImageToText(),
new UploadFile("image", fsImage, "image"));
// Poll for Job Completion Status
GetTextGenerationStatusResponse status = new();
while (status.JobState is BackgroundJobState.Queued or BackgroundJobState.Started)
{
status = client.Get(new GetTextGenerationStatus { JobId = response.JobId });
Thread.Sleep(1000);
}
if (status.Results?.Count > 0)
{
var answer = status.Results[0].Text;
}
INFO
Ensure that the ComfyUI Agent has the Florence 2 model downloaded and installed for the Image-To-Text functionality to work.
This can be done by setting the DEFAULT_MODELS environment variable in the .env file to include image-to-text
Support for Ollama Vision Models
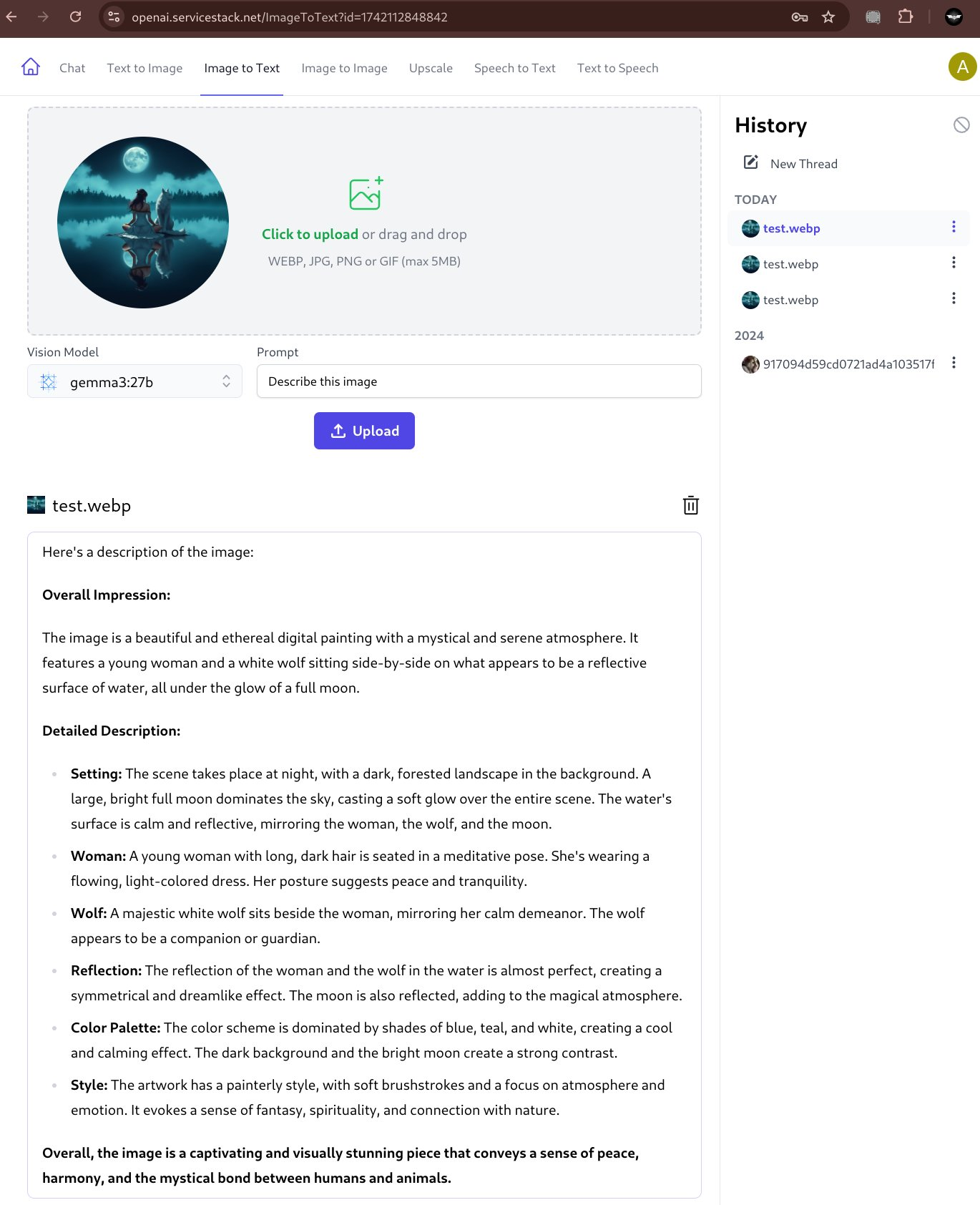
By default ImageToText uses a purpose-specific Florence 2 Vision model with ComfyUI for its functionality which is capable of generating a very short description about an image, e.g:
A woman sitting on the edge of a lake with a wolf
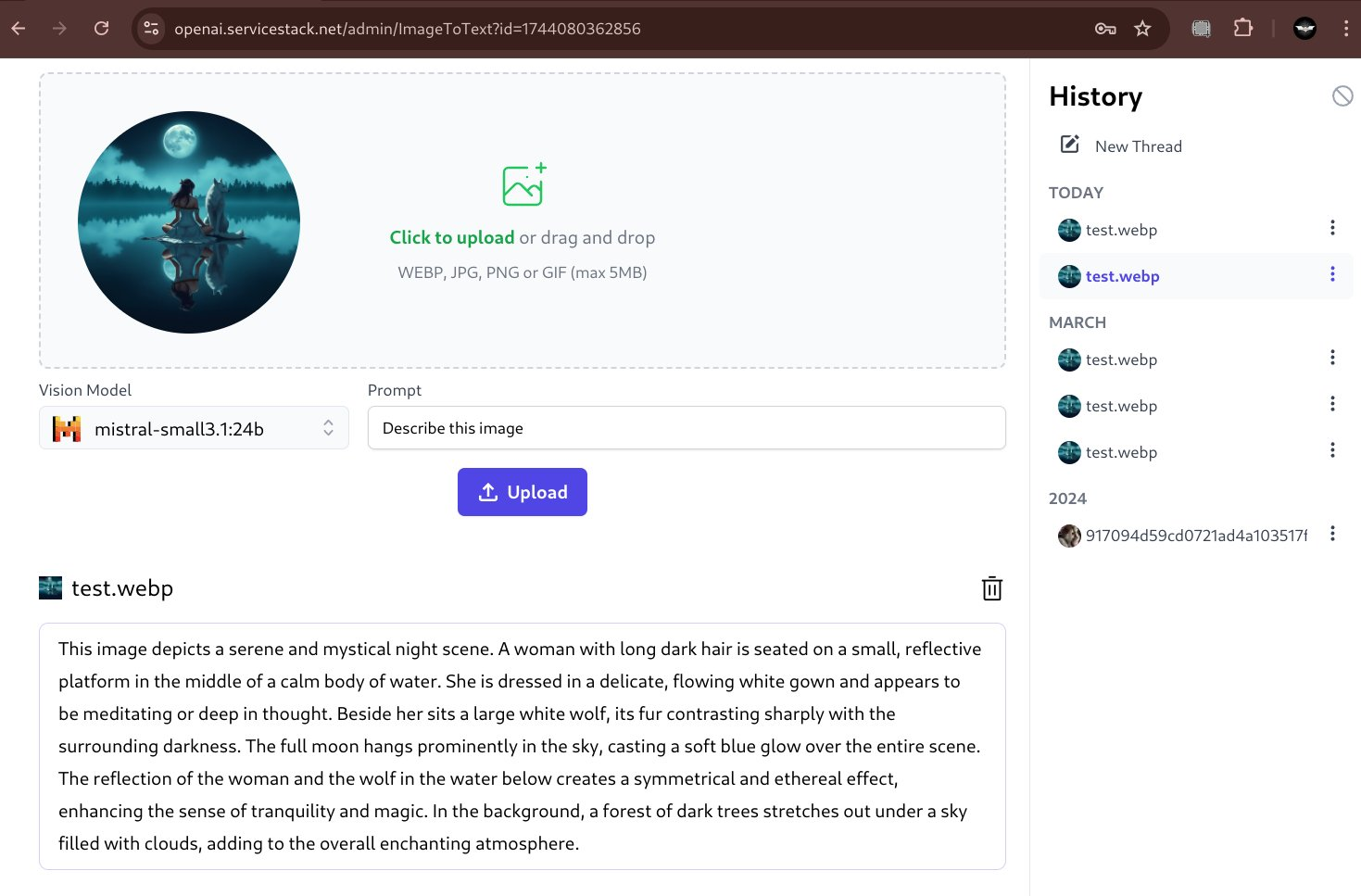
But with LLMs gaining multi modal capabilities and Ollama's recent support of Vision Models we can instead use popular Open Source models like Google's gemma3:27b or Mistral's mistral-small:24b to extract information from images.
Both models are very capable vision models that's can provide rich detail about an image:
Describe Image
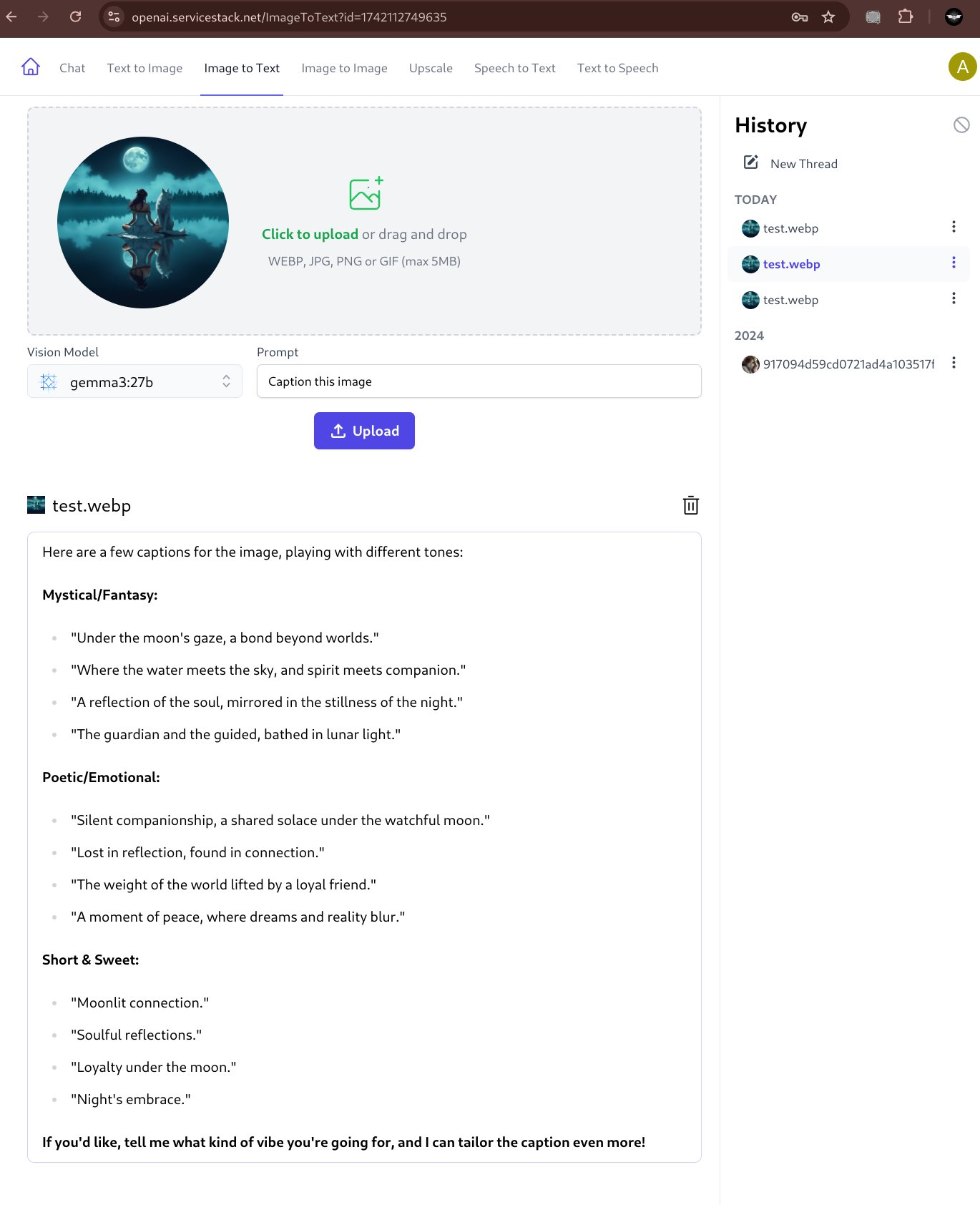
Caption Image
Although our initial testing sees gemma being better at responding to a wide variety of different prompts, e.g:
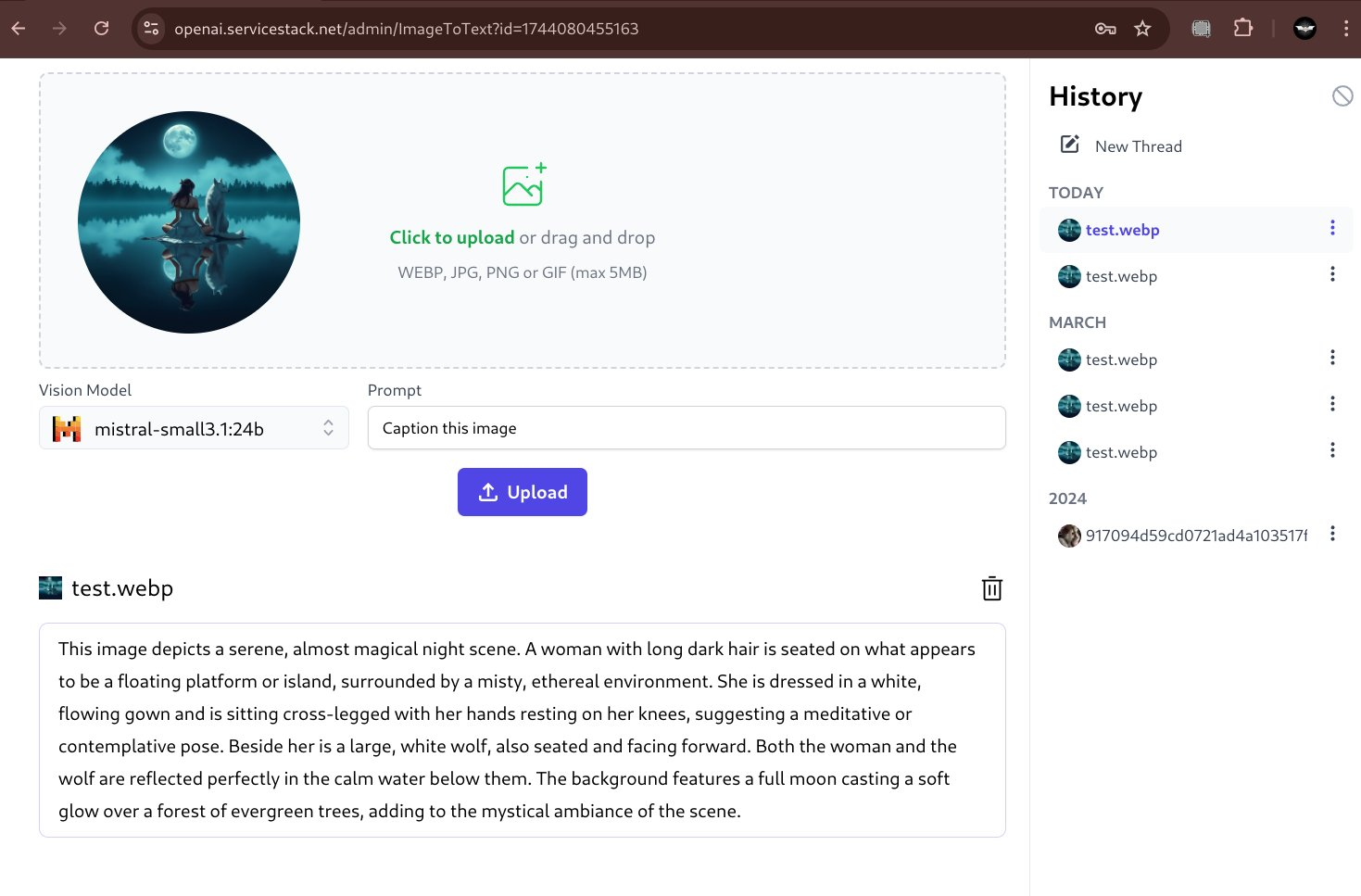
Support OllamaGenerate Endpoint
To support Ollama's vision models AI Server added a new feature pipeline around Ollama's generate completion API:
ImageToText- Model - Whether to use a Vision Model for the request
- Prompt - Prompt for the vision model
OllamaGeneration: Synchronous invocation of Ollama's Generate APIQueueOllamaGeneration: Asynchronous or Web Callback invocation of Ollama's Generate APIGetOllamaGenerationStatus: Get the generation status of an Ollama Generate API