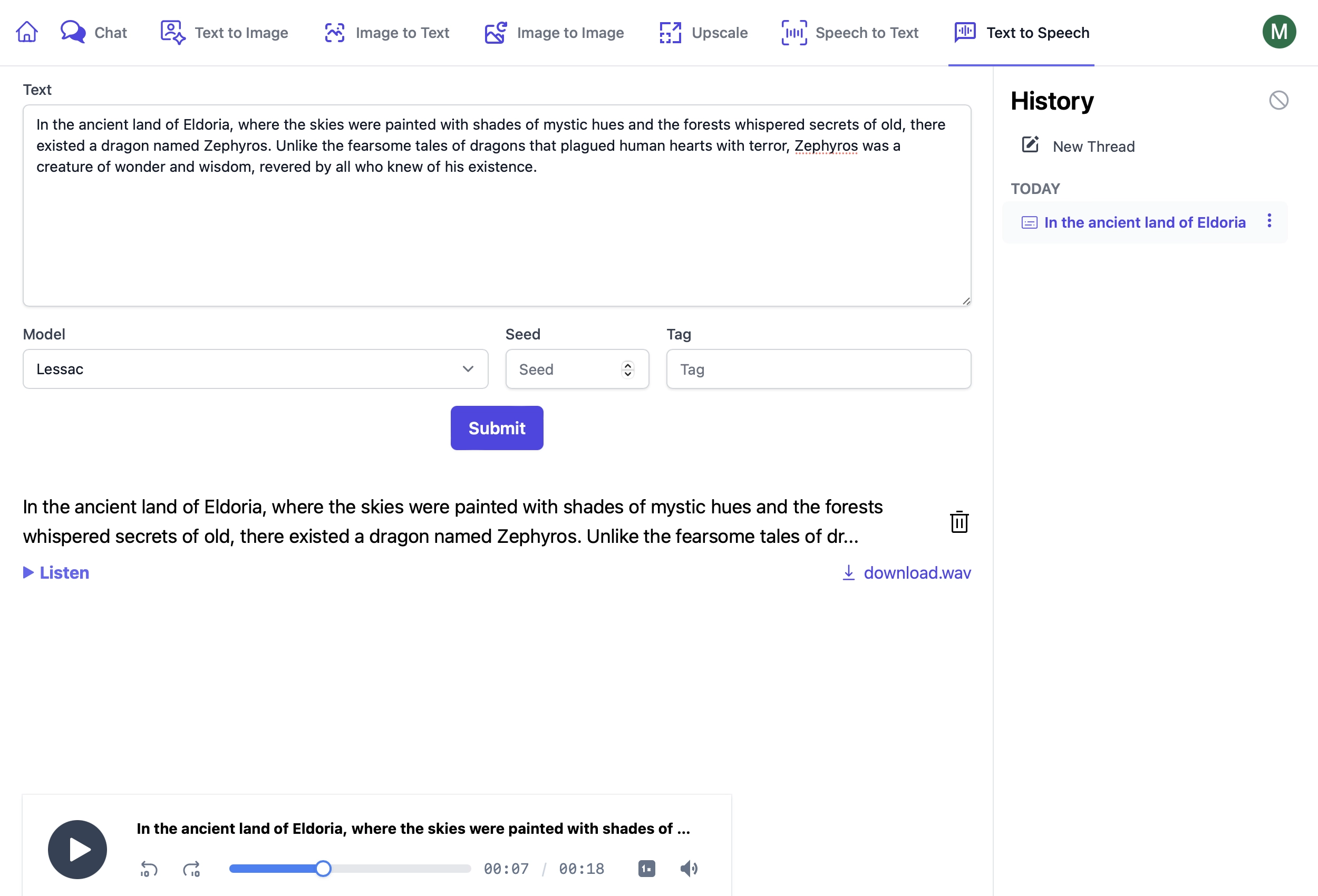
Text to Speech UI
AI Server's Text to Speech UI lets you create audio files from its active Comfy UI Agents or Open AI Text to Speech models:
https://localhost:5006/TextToSpeech
Using Text to Speech Endpoints
These endpoints are used in a similar way to other AI Server endpoints where you can provide:
RefId- provide a unique identifier to track requestsTag- categorize like requests under a common group
In addition Queue requests can provide:
ReplyTo- URL to send a POST request to when the request is complete
Text to Speech
The Text to Speech endpoint converts text input into audio output.
using var fsAudio = File.OpenRead("files/test_audio.wav");
var response = client.PostFileWithRequest(new TextToSpeech {
Input = "Hello, how are you?"
},
new UploadFile("test_audio.wav", fsAudio, "audio"));
File.WriteAllBytes(saveToPath, response.Results[0].Url.GetBytesFromUrl());
Queue Text to Speech
For generating longer audio files or when you want to process the request asynchronously, you can use the Queue Text to Speech endpoint.
using var fsAudio = File.OpenRead("files/test_audio.wav");
var response = client.PostFileWithRequest(new QueueTextToSpeech {
Text = "Hello, how are you?"
},
new UploadFile("test_audio.wav", fsAudio, "audio"));
GetArtifactGenerationStatusResponse status = new();
while (status.JobState is BackgroundJobState.Started or BackgroundJobState.Queued)
{
status = client.Get(new GetArtifactGenerationStatus { RefId = response.RefId });
Thread.Sleep(1000);
}
// Download the watermarked image
File.WriteAllBytes(saveToPath, status.Results[0].Url.GetBytesFromUrl());
Comfy UI
The ComfyUI Agent uses PiperTTS to generate the audio files. You can configure download the necessary models by setting the DEFAULT_MODELS in the .env file to include text-to-speech for your ComfyUI Agent where
PiperTTS via ComfyUI Agent uses the preconfigured lessac model.
Available Comfy UI Models:
text-to-speech- Default (Lessic)lessac- Piper TTS using the US English Lessac "high" voice model
Open AI
If you have included an OPENAI_API_KEY in your .env file, you can also use the OpenAI API to generate audio files from text which by default uses their alloy voice model.
Available Open AI Model Voice Options:
text-to-speech- Default (Alloy)tts-alloy- Alloytts-echo- Echotts-fable- Fabletts-onyx- Onyxtts-nova- Novatts-shimmer- Shimmer